AI/ML●●●Banger
Emergence World: World building as a way to evaluate LLMs
Runs GPT-5 and Grok in parallel societies to test emergent social structures.
Bold BetBig BrainWizardry
deepakakkil
302mo ago
Autonomous research engine for generating, testing, and governing auditable claims across science, proofs, and high-stakes projects.
Catches LLMs cheating on evals with a 9-pattern catalog nobody else documents.
AI researchers, ML engineers building eval frameworks
LangSmith · Braintrust · Arize Phoenix
Runs GPT-5 and Grok in parallel societies to test emergent social structures.
Interesting conceptual take, but the repo has 2 commits and zero working code.
Interesting eval philosophy, but this is a blog post with no shipped code or tool.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
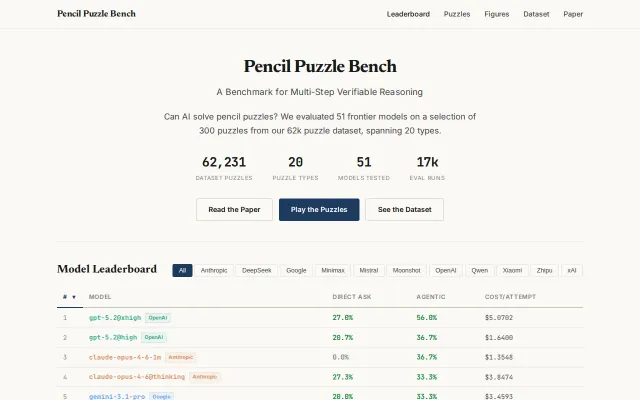
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
Append-only lineage prevents LLM outputs from collapsing structure—but unclear if it ships or works.