AI/ML●●Solid
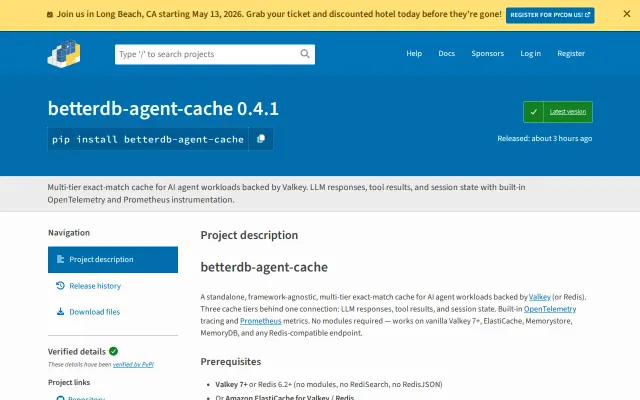
Agent cache for Valkey, now in Python with bundled LiteLLM pricing
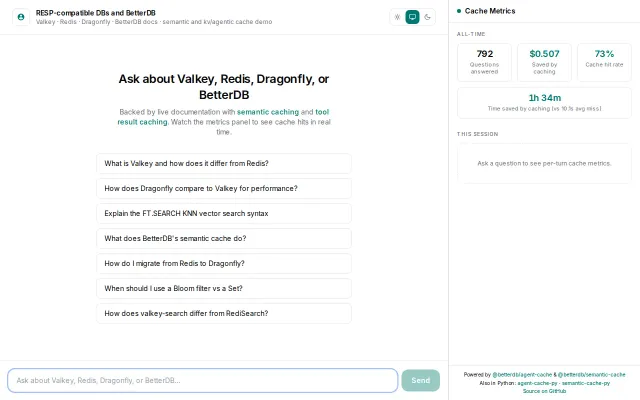
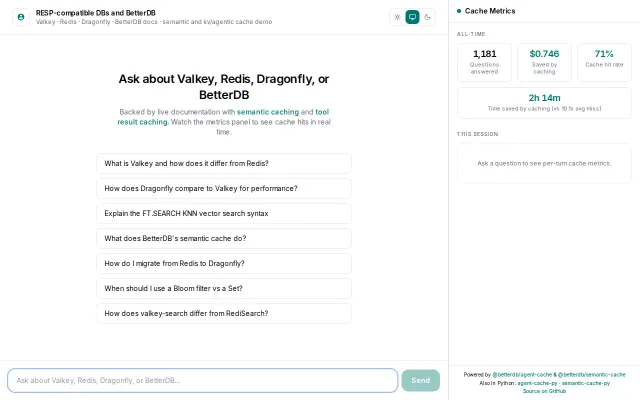
Multi-tier cache for AI agents with built-in OpenTelemetry and Prometheus metrics.
SlickSolve My Problem
kaliades
101mo ago
First semantic cache handling Valkey Search 1.2 divergences without silent breaks.
Backend engineers using Valkey for LLM caching
RedisVL · LangChain · LiteLLM
@betterdb/semantic-cache is a standalone semantic cache backed by valkey-search. No framework coupling - works with any LLM client. Every check() and store() emits an OTel span and increments Prometheus counters and histograms out of the box. No instrumentation code required. MIT. Optional LangChain and Vercel AI SDK adapters. Works on self-hosted Valkey, ElastiCache for Valkey, and Memorystore for Valkey.
https://www.npmjs.com/package/@betterdb/semantic-cache
The Valkey Search 1.2 divergences from RediSearch that required explicit handling are in the changelog.
Multi-tier cache for AI agents with built-in OpenTelemetry and Prometheus metrics.
Two-tier caching saves real money, shown live on the dashboard.
Zero-config OTLP listener beats Jaeger for local trace debugging sessions.
Replaces ClickHouse clusters with a single DuckDB container handling 140K events/sec on an M1 Max.
Tool result caching for agents when GPTCache and LangChain already do semantic caching.
AST parsing beats prompt-scoped AI by finding every DB call across framework boundaries.