AI/ML●●Solid
I benchmarked how good LLMs are at proofreading English
Agent loop proofreading evals where HELM and LMSys are too generic.
Solve My ProblemShip It
artursapek
322mo ago
Adversarial multi-turn benchmark for LLM debate quality, using side-swapped matchups and multi-model judging to rank models by judged debate performance.
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
LLM researchers and AI developers evaluating model capabilities
LMSys Arena · HELM · BigBench
Agent loop proofreading evals where HELM and LMSys are too generic.
Orchestrates real-time skepticism between models to catch hallucinations before you see them.
2B model beats 12B on some tasks, saving hardware costs for edge deployment.
Sequential-dispatch methodology corrects 20x overestimation in prior WebGPU benchmarks.
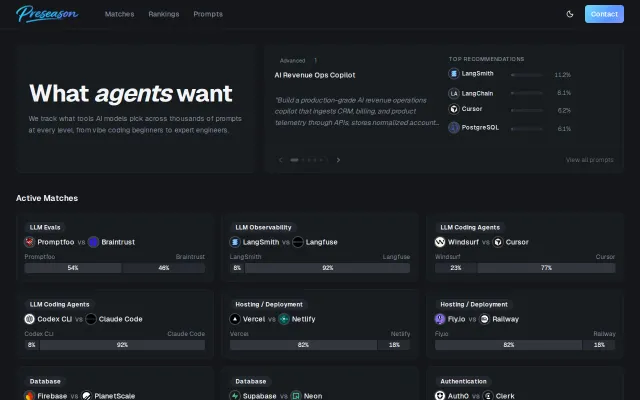
Tracks which dev tools AI agents actually choose across thousands of prompts.
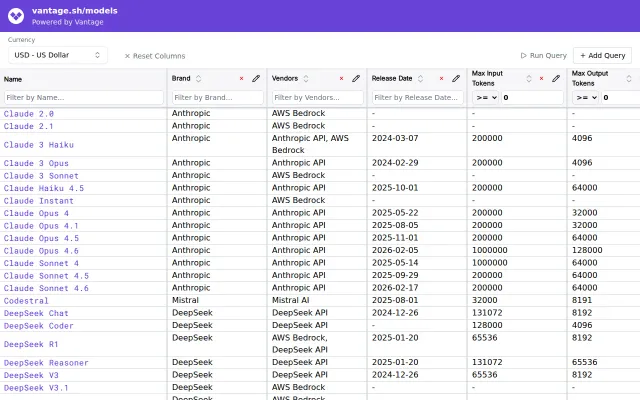
ec2instances.info for LLMs—clean comparison table with real-time pricing and benchmarks.