AI/ML●●Solid
LLM Debate Benchmark
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
Big BrainDark Horse
zone411
932mo ago
2B model beats 12B on some tasks, saving hardware costs for edge deployment.
ML engineers, edge AI developers
LMSys Chatbot Arena · Hugging Face Open LLM Leaderboard
Side-swapped debate matchups expose model weaknesses standard benchmarks miss.
Unified memory trick lets a 2B model beat 12B; trains on MacBook with zero cloud costs.
Git-like branching for columnar data with DuckDB-beating benchmarks from pure JVM.
100K-turn benchmark tests situational memory retrieval where others stop at 600.
Side-by-side model comparison eliminates guessing which speech engine fits your hardware.
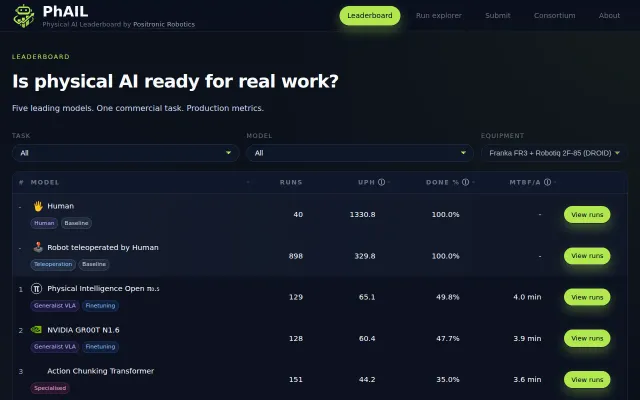
Real-robot production benchmarks proving AI is still 20x slower than humans.