AI/ML●●Solid
Speechos – Benchmark 25 speech AI models locally, no cloud needed
Side-by-side model comparison eliminates guessing which speech engine fits your hardware.
Dark HorseSolve My Problem
hamuf
114mo ago
A lightweight library for normalizing speech transcripts before computing WER
Fixes WER scores by normalizing '$50' and 'fifty dollars' as equivalent.
STT engineers, ML researchers evaluating speech models
jiwer · SpeechBrain · Kaldi scoring tools
Side-by-side model comparison eliminates guessing which speech engine fits your hardware.
Voice-specific prompt injection framework, but testing methodology alone isn't a shipping product.
Yet another on-device speech wrapper, but iOS-only with Android still coming soon.
Exposes 230% Arabic token tax that nobody talks about in pricing.
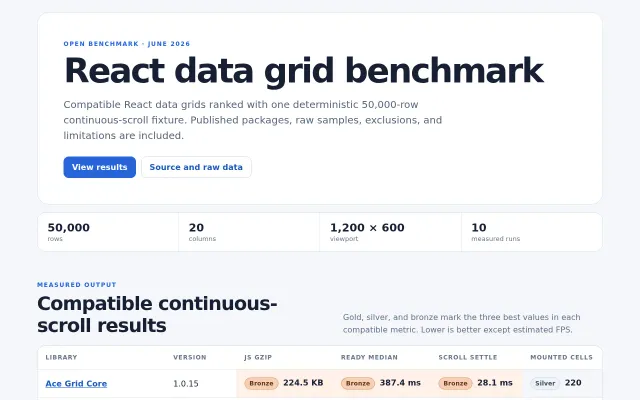
Raw browser samples and deterministic fixtures make this benchmark actually reproducible.
Tests Deepgram and AssemblyAI on actual crosstalk instead of clean audiobook samples.