AI/ML●●Solid
Reproducible benchmark – OpenAI charges 1.5x-3.3x more for non-English
Exposes 230% Arabic token tax that nobody talks about in pricing.
Dark HorseBig Brain
vfalbor
102mo ago
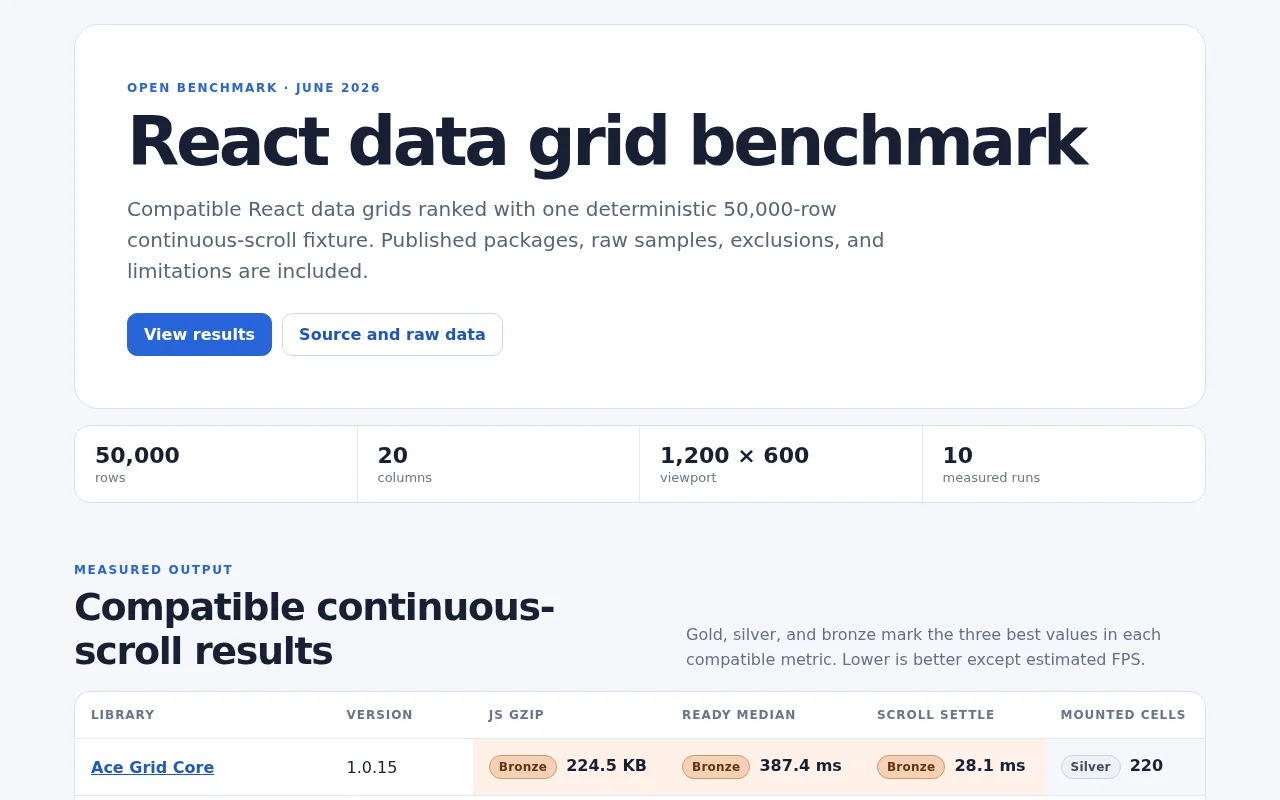
Exposes 230% Arabic token tax that nobody talks about in pricing.
This is a compact, dependency-free TestBed<MyModel> harness that forces models to predict next-step bitset inputs with deterministic seeds — clever for reproducible, low-level experimentation. Execution is pragmatic (header-only, quick compile, clear API), but there's no showcased model that actually passes the tests and the scope is deliberately narrow, so it’s more of a useful lab tool than a breakthrough benchmark.
Ed25519-signed benchmark receipts when most AI claims are unverifiable marketing.
Fuchsia-inspired capability model for agent benchmarks solves reproducibility existing tools ignore.
Shows retrieval metrics lie—answer correctness ranges from 23% to 92% across identical scores.
90.3 BrowseComp score with verification-centric model architecture.