AI/ML●●●Banger
Rapid-MLX – Run local LLMs on Mac, 2-3x faster than alternatives
Claims 4.2x Ollama speed with 0.08s cached TTFT on Apple Silicon.
WizardrySolve My Problem
raullen
941mo ago

Unlocks Apple's locked LLM with OpenAI-compatible server for existing SDKs.
Mac developers, privacy-focused AI users
Ollama · LM Studio · MLX
Claims 4.2x Ollama speed with 0.08s cached TTFT on Apple Silicon.
MLX-powered local TTS plugin for OpenClaw—elegant but audience is Apple Silicon only.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.
M3/M4 thermal-manager unlock that most older fan tools don't handle.
Wraps mlx-lm fine-tuning into a guided desktop UI, but local LLM tools are crowded.
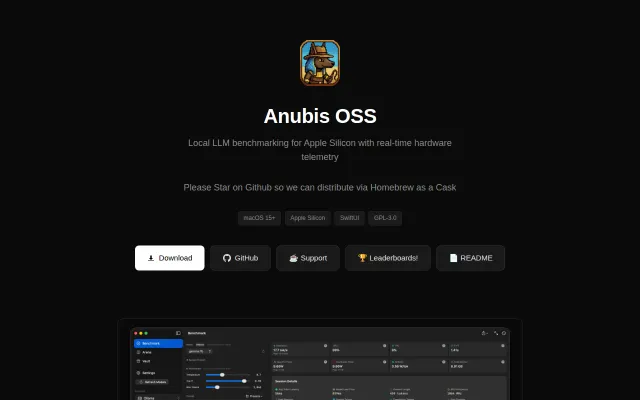
Real-time power-per-token metering across GPU/CPU/ANE—no other macOS LLM tool correlates hardware telemetry.