AI/ML●●●Banger
iPhone ANE holds LLM tok/s while MLX and LiteRT thermal-throttle
LiteRT beats MLX on Gemma memory while CoreML sips power on the Neural Engine.
Dark HorseBig BrainSolve My Problem
mlboy
1012d ago
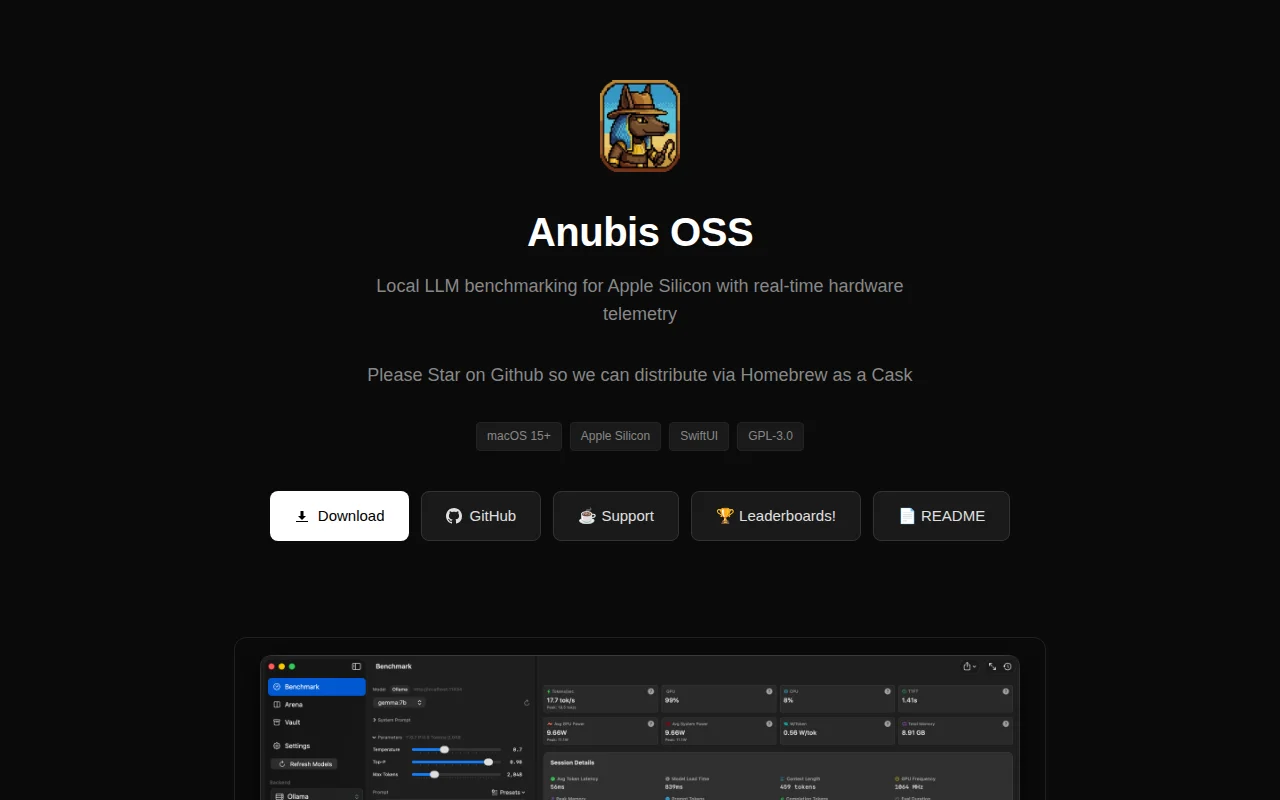
Real-time power-per-token metering across GPU/CPU/ANE—no other macOS LLM tool correlates hardware telemetry.
ML engineers and developers optimizing LLM inference on Apple Silicon hardware
Ollama · LM Studio · promptfoo
The narrative around AI has been almost entirely cloud-centric. You send a prompt to a data center, tokens come back, and you try not to think about the latency, cost, or privacy implications. For a long time, that was the only game in town.
Apple Silicon - from M1 through the M4 Pro/Max shipping today, with M5 on the horizon - has quietly become one of the most capable local AI compute platforms on the planet. The unified memory architecture means an M4 Max with 128GB can run models that would require a dedicated GPU workstation elsewhere. At laptop wattages. Offline. Without sending a single token to a third party.
This shift is legitimately great for all parties (except cloud ones that want your money), but it comes with an unsolved problem: we don't have great, community-driven data on how these machines actually perform in the wild.
That's why I built Anubis OSS.
The Fragmented Local LLM Ecosystem
If you've run local models on macOS, you've felt this friction. Chat wrappers like Ollama and LM Studio are great for conversation but not built for systematic testing. Hardware monitors like asitop show GPU utilization but have no concept of what model is loaded or what the prompt context is. Eval frameworks like promptfoo require terminal fluency that puts them out of reach for many practitioners.
None of these tools correlate hardware behavior with inference performance. You can watch your GPU spike during generation, but you can't easily answer: Is Gemma 3 12B Q4_K_M more watt-efficient than Mistral Small 3.1 on an M3 Pro? How does TTFT scale with context length on 32GB vs. 64GB?
Anubis answers those questions. It's a native SwiftUI app - no Electron, no Python runtime, no external dependencies - that runs benchmark sessions against any OpenAI-compatible backend (Ollama, LM Studio, mlx-lm, and more) while simultaneously pulling real hardware telemetry via IOReport: GPU/CPU utilization, power draw in watts, ANE activity, memory including Metal allocations, and thermal state.
Why the Open Dataset Is the Real Story
The leaderboard submissions aren't a scoreboard - they're the start of a real-world, community-sourced performance dataset across diverse Apple Silicon configs, model families, quantizations, and backends.
This data is hard to get any other way. Formal chipmaker benchmarks are synthetic. Reviewer benchmarks cover a handful of models. Nobody has the hardware budget to run a full cross-product matrix. But collectively, the community does.
For backend developers, the dataset surfaces which chip/memory configurations are underperforming their theoretical bandwidth, where TTFT degrades under long contexts, and what the real-world power envelope looks like under sustained load. For quantization authors, it shows efficiency curves across real hardware, ANE utilization patterns, and whether a quantization actually reduces memory pressure or just parameter count.
Running a benchmark takes about two minutes. Submitting takes one click.
Your hardware is probably underrepresented. The matrix of chip × memory × backend × thermal environment is enormous — every submission fills a cell nobody else may have covered.
The dataset is open. This isn't data disappearing into a corporate analytics pipeline. It's a community resource for anyone building tools, writing research, or optimizing for the platform.
Anubis OSS is working toward 75 GitHub stars to qualify for Homebrew Cask distribution, which would make installation dramatically easier. A star is a genuinely meaningful contribution.
Download from the latest GitHub release — notarized macOS app, no build required Run a benchmark against any model in your preferred backend Submit results to the community leaderboard Star the repo at github.com/uncSoft/anubis-oss
LiteRT beats MLX on Gemma memory while CoreML sips power on the Neural Engine.
The repo does one practical thing well: quantify the real-world impact of Apple Silicon's unified memory on analytics by running six TPC-H queries plus a GPU-favorable QX and shipping the raw charts and code. It's specific and empirical — you get MLX vs NumPy vs DuckDB numbers and PNGs, not just hand-wavy claims — but it's narrowly scoped to M4 hardware and small-ish scales, so its conclusions are useful for experimentation rather than sweeping generalization.
Only Apple Silicon toolkit streaming GCS data during audio fine-tuning without OOM.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.
Useful lookup table, but spreadsheets and Reddit threads already solve this better.
Fine-tune LLMs on Apple Neural Engine using reverse-engineered private frameworks — genuinely novel approach.