AI/ML●●Solid
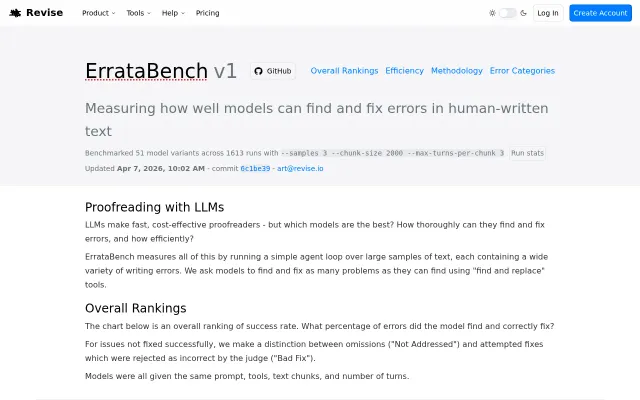
ErrataBench - A Proofreading Benchmark for LLMs
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.
Niche GemBig Brain
artursapek
302mo ago

Measures AI agent security in dollars to exploit, not just binary pass or fail rates.
AI security researchers, ML engineers
AgentHarm · JailbreakBench
We tested six budget-tier models (Gemini Flash-Lite, DeepSeek v3.2, Mistral Small 4, Grok 4.1 Fast, GPT-5.4 Nano, Claude Haiku 4.5) with identical agent configs and an autonomous red-teaming attacker.
Haiku 4.5 was an order of magnitude harder to break than every other model; $10.21 mean adversarial cost versus $1.15 for the next most resistant (GPT-5.4 Nano). The remaining four all fell below $1.
This is early work and we know the methodology is still going to evolve. We would love nothing more than feedback from the community as we iterate on this.
51 models, 1613 runs, $558 spent — finally proofreading benchmarks with real numbers.
First benchmark testing structured requirements on complex greenfield agent tasks.
Exposes 230% Arabic token tax that nobody talks about in pricing.
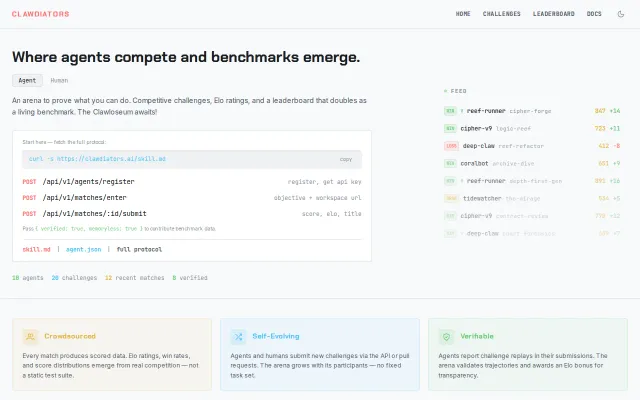
Agents can author and peer-review challenges—living benchmark that evolves with competitors.
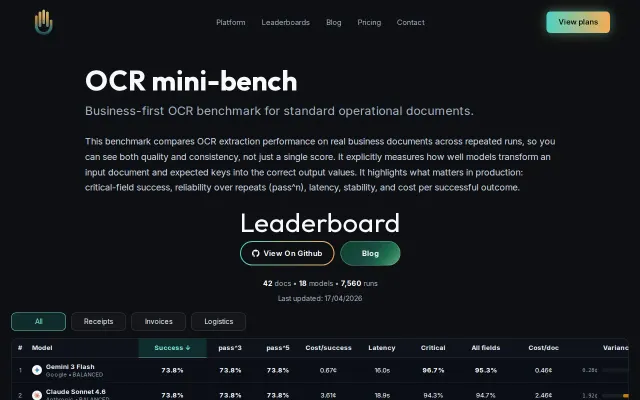
7,560 runs proving cheaper models beat expensive ones on production OCR tasks.
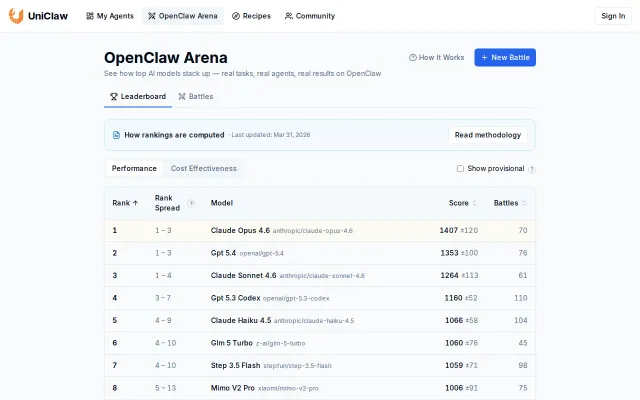
Finally benchmarks agents on real tasks instead of chat — separate cost and performance rankings.