Developer Tools●Mid
Mo – checks GitHub PRs against decisions approved in Slack
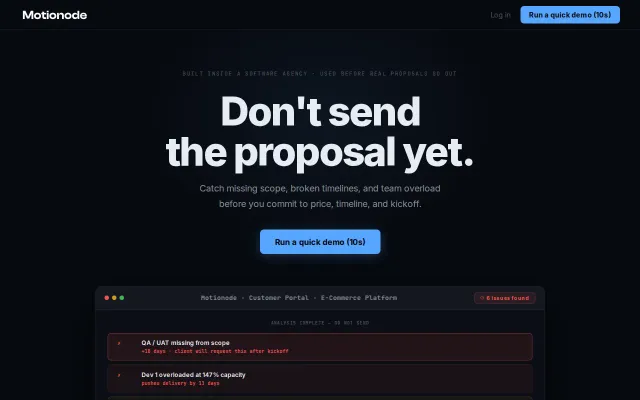
Slack-to-PR decision tracking, but landing page shows a different product entirely.
Solve My ProblemNiche Gem
oscarcaldera
202mo ago
Benchmark your CLAUDE.md against your own PRs
Mining your own PRs as benchmarks beats generic SWE-bench tasks for agent config tuning.
Developers using Claude Code with CLAUDE.md agent configuration files
SWE-bench · Aider · Claude Code
Slack-to-PR decision tracking, but landing page shows a different product entirely.
Slack-to-PR decision tracking, but landing page shows a different product entirely.
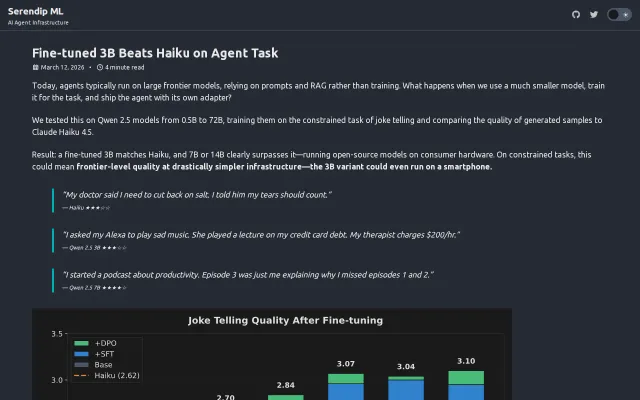
Fine-tuned 3B Qwen matches Haiku on jokes, validating small models for constrained agent tasks.
Benchmarked dead code finder across FastAPI, Pydantic, Flask—but Vulture, Bandit already solve this.
Proves speculative decoding slows down 4B models on 4-core CPUs despite marketing claims.
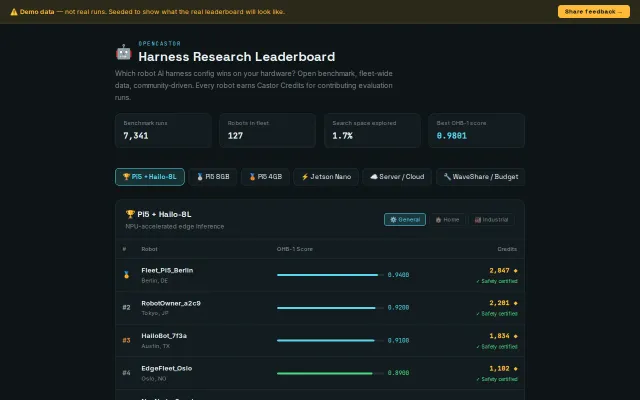
263k config search space benchmarked across robot fleets—nothing like this exists for robotics AI.