Developer Tools●●Solid
Nomik-Open-source AI-native knowledge graph for code(Neo4j and MCP)
Graph-aware code context for AI agents beats file-dumping, but Cody and Continue exist.
Big BrainNiche GemSolve My Problem
willfreed1
103mo ago
Build local, queryable packs from videos, articles, podcasts, and local files. Query them through MCP with your AI agent, or use a local model to explore them directly.
Cross-agent packs work with Claude Code, Cursor, and Ollama — build once, query anywhere.
Developers using AI agents, knowledge workers, local-first advocates
AnythingLLM · PrivateGPT · Mem.ai
This started from a pretty personal use case.
There was this very technical person I follow who would go live on YouTube from time to time. He has a ton of experience, and would casually drop really good insights about software architecture, engineering tradeoffs, and just general "you only learn this after years" kind of stuff. He also posts shorter clips, but I wanted something else: I wanted that knowledge to be always there, queryable whenever I needed it.
At the same time, I was also trying to understand what RAG actually is in practice, and how to learn applied AI by building something real instead of just reading about it.
My first thought was: ok, this probably has to be fully local. I assumed if I want to query my own stuff locally, then I need to use a local LLM. So I looked into Ollama and thought, alright, I can build this on top of that and just query everything on my machine. At that point I also had some pretty wrong assumptions about local models and resource usage.
After building the first version, it worked, but the result felt a bit underwhelming. Retrieval itself was useful, but the final answer didnt feel as smart as I expected. I use Codex and Claude Code a lot in my daily workflow, so maybe I was unfairly expecting something that felt more "intelligent", or at least looked that way.
Then after a lot of tests with agents (Codex and Claude Code, I use both), I realized something kind of obvious: the Ollama part was mostly just taking the retrieved chunks and turning them into a proper answer. And if that's the job, why couldnt an agent do the same thing?
So I tried wiring it through MCP.
That was the moment where the project really clicked for me. The answers became way better structured, the whole thing felt much smarter, and more importantly, it fit directly into how I already work. Instead of having a seperate tool where I go ask questions, the knowledge just becomes available inside the agent workflow itself. The agent can retrieve it, use it, suggest things, and continue the task.
That was exactly what I wanted, maybe even better than what I had in mind when I started.
The best part for me is that once it's set up, it kinda disappears. I just keep adding YouTube videos, podcasts, and files, and then that context is available while I'm working with AI agents. It stops feeling like "a RAG demo" and starts feeling like part of the actual workflow.
What started as a small local RAG experiment ended up turning into something much more useful than I originally imagined.
Graph-aware code context for AI agents beats file-dumping, but Cody and Continue exist.
YouTube + MCP servers means Claude can actually query video lectures semantically.
Embeddings + vector search on AI skill graph—but is this a demo or a product you can actually use?
Cross-project knowledge graph with contradiction detection when Cursor and Cody already exist.
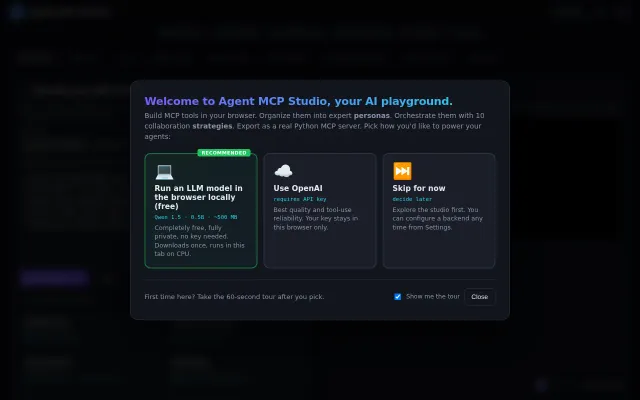
Full MCP agent studio running entirely in-browser via Pyodide and DuckDB-WASM.
Auditable agent decisions via DAG receipts—unlike prompt-dependent LLMs, this proves reasoning.