Infrastructure●●Solid

Orchestera – Managed Apache Spark on Kubernetes in Your Own AWS Account
Spark without Databricks markup, but Kubernetes management is still ops work.
Solve My ProblemDark Horse
iamspoilt
313mo ago
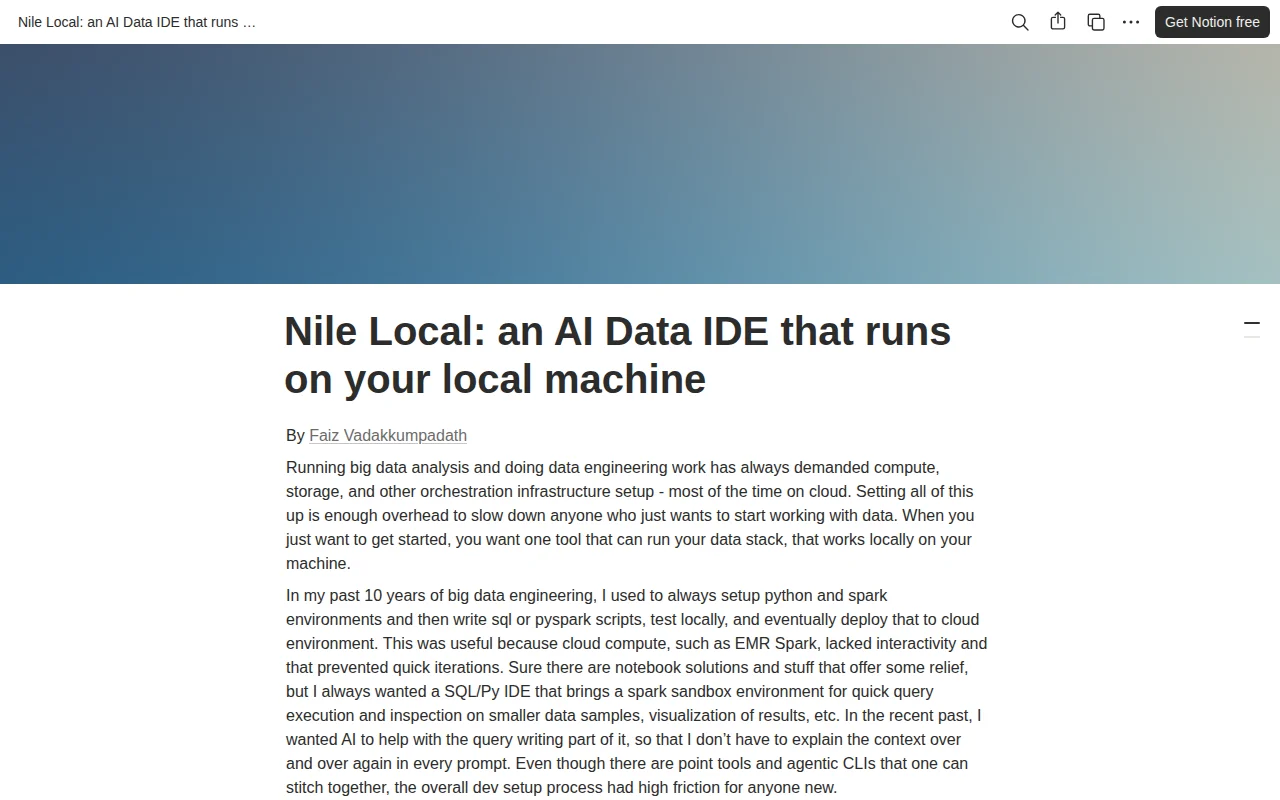
Zero-cloud data stack with built-in LLMs, but DuckDB already does local analytics.
Data engineers, analysts working offline or on side projects
DuckDB · Databricks Community Edition · JupyterLab
You get data lake like catalog, zero-ETL, lineage, versioning, and analytics running entirely on your machine. You can import from a database, webpage, CSV, etc. and query in natural language or do your own work in SQL/Pyspark. Connect to local models like Gemma or cloud LLMs like Claude for querying and analysis. You don’t have to setup local LLMs, it comes built in.
This is completely free. No cloud account required.
Downloading the software - https://getnile.ai/downloads
Watch a demo - https://www.youtube.com/watch?v=C6qSFLylryk
Check the code repo - https://github.com/NileData/local
This is still early and I'd genuinely love your feedback on what's broken, what's missing, and if you find this useful for your data and analytics work.
Spark without Databricks markup, but Kubernetes management is still ops work.
Neuromorphic engine on a deterministic rhythm, but v0.2 design-freeze with no working demo yet.
Orthogonal Procrustes migration means embedding model upgrades without reindexing.
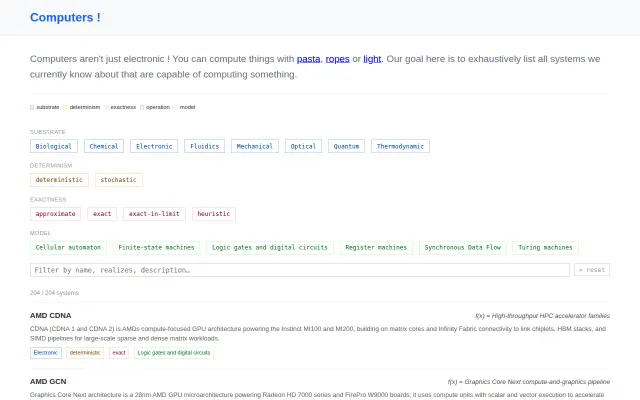
Curated list of computing substrates lacks depth beyond basic taxonomy tags.
Apache Iceberg for observability data cuts costs versus Datadog and Honeycomb pricing.
Receipt-backed promotion decisions with SHA-256 hashes and commit linkage is a practical, low-ceremony way to make spotlight selections auditable. The zero-dependency CLI, freeze modes and drift reports show this was designed for governance-first catalogs rather than casual lists — useful and sensible, but narrowly aimed.