AI/ML●●●Banger
1-Bit Bonsai, the First Commercially Viable 1-Bit LLMs
1-bit weights matching 8B model performance while running 132 tokens/sec on M4 Pro.
Big BrainZero to OneWizardry
PrismML
4301532mo ago
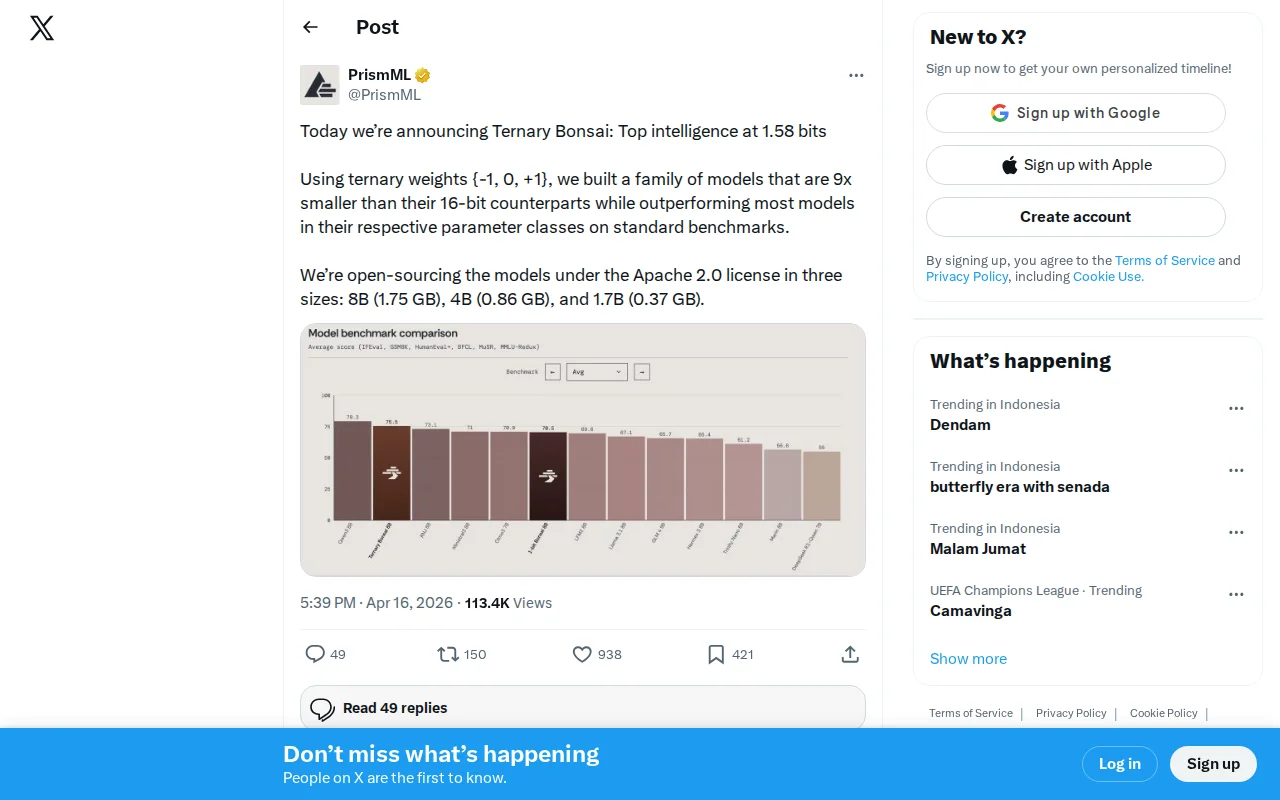
Ternary weight quantization claims are bold, but where's the code or paper?
ML engineers and researchers interested in model quantization
bitsandbytes · AWQ · GPTQ
1-bit weights matching 8B model performance while running 132 tokens/sec on M4 Pro.
Bonsai 1-bit models make Pi 4 LLMs viable where Ollama usually chokes.
Autonomous agent wrote custom Metal kernels boosting decode speed 42% over upstream llama.cpp.
Native ternary training beats post-training quantization for memory efficiency.
1.58-bit ternary neural networks in 30 KB of vanilla JavaScript — no dependencies.
Fills the TypeScript gap that Semgrep's official AI best practices pack misses.

