AI/ML●●●Banger
3.125-Bit LLM quantization bypassing tensor cores
Replaces Tensor Cores with LUTs and bitwise ops for 3-bit edge inference.
Big BrainBold Bet
dmaniss
302mo ago
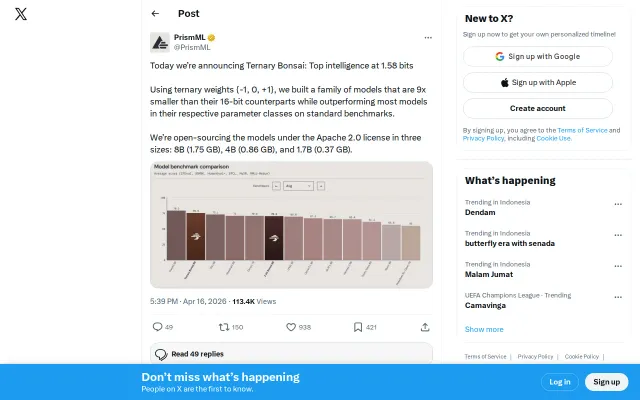
1-bit weights matching 8B model performance while running 132 tokens/sec on M4 Pro.
ML engineers, edge AI developers, robotics teams
BitNet · Microsoft BitNet b1.58 · LLM.int8()
Replaces Tensor Cores with LUTs and bitwise ops for 3-bit edge inference.
E8 lattice codebooks beat GPTQ at 2-4 bpw with fused CUDA kernel skipping weight materialization.
Ternary weight quantization claims are bold, but where's the code or paper?
Confidence-based routing automatically hands off uncertain tokens to cloud models seamlessly.
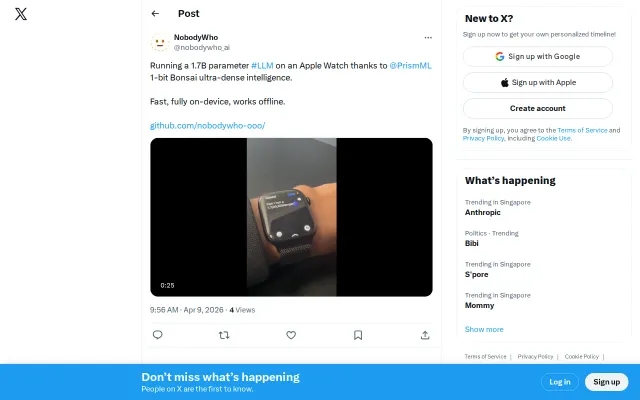
Runs a 1.7B LLM offline on Apple Watch using 1-bit quantization.
Bonsai 1-bit models make Pi 4 LLMs viable where Ollama usually chokes.