AI/ML●●Solid
OpenClacky – A token-efficient personal agent written in Ruby
94.9% cache hit rate cuts token costs, but AI agent wrappers are crowded.
SlickShip It
gemHunter
306d ago
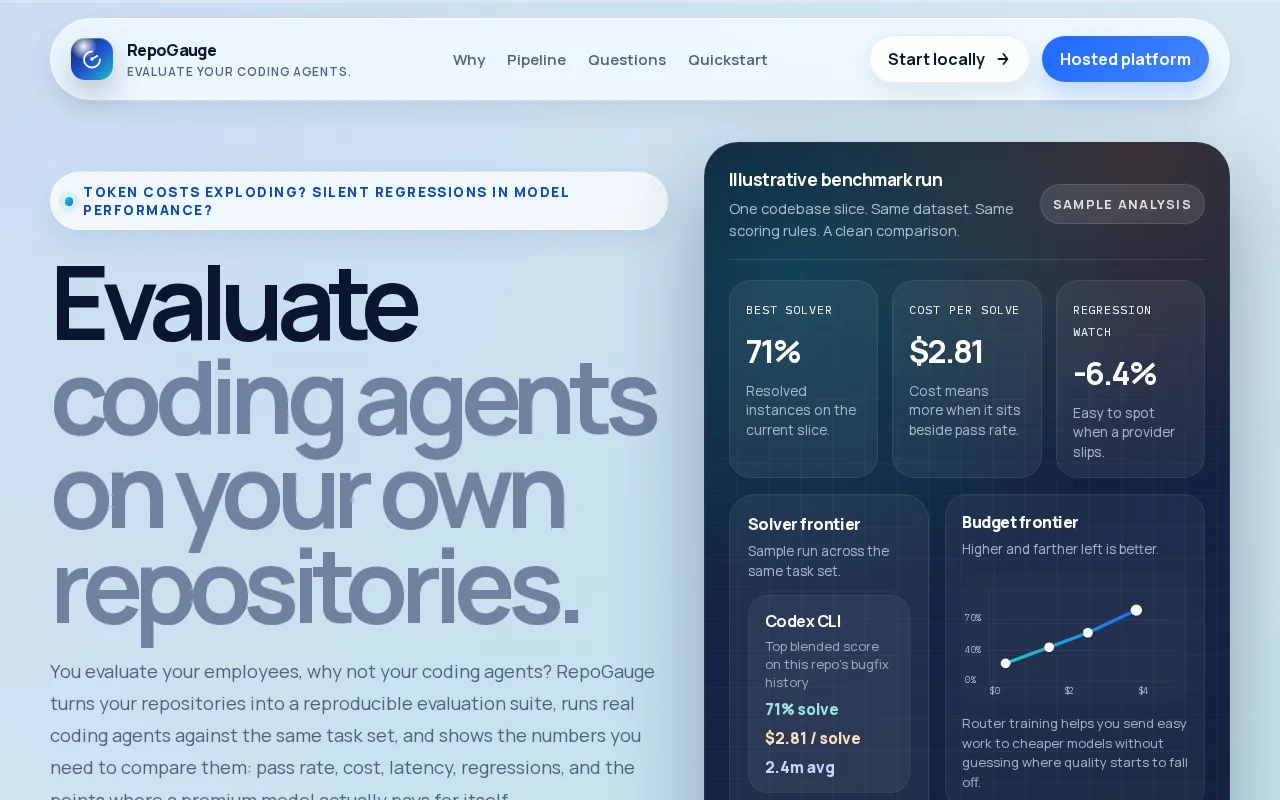
Mining your own bugfix history for evals beats public benchmarks that don't match your codebase.
Engineering teams evaluating AI coding assistants
SWE-bench · Aider · Codex CLI
I did a few manual analyses but found it non-trivial to compare across models due to difference in token caching and tool-use efficiency and so wanted a tool for repeatable evaluations.
So the goal was an OSS tool get data to help answer questions like:
“Would Sonnet have solved most of the issues we gave Opus? "How much would that have actually saved?” “What about OSS models like Kimi K2.5 or GLM-1?” “The vibes are off, did model performance just regress from last month?”
Right now the project is a bit medium-rare - but it works end-to-end. I’ve run it successfully against itself, and I’m waiting for my token limits to reset so I can add support for more languages and do a broader run. I'm already seeing a few cases where I could've used 5.4-mini instead of 5.4 for some parts of implementation.
I’d love any feedback, criticism, and ideas. I am especially interested if this is something you might pay for as a managed service or if you would contribute your private testcases to a shared commons hold-out set to hold AI providers a bit more accountable.
https://repogauge.org [email protected] https://github.com/s1liconcow/repogauge
Thanks! David
94.9% cache hit rate cuts token costs, but AI agent wrappers are crowded.
Billion-token token spend recap, but lacks concrete deliverable or technical substance.
Transparent benchmarks show 39% cost cuts — rare to see real numbers in AI tooling.
Claude Code hooks that cut token costs, but only matters if you're burning through CLI agent budgets.
Pre-session tool selection via 102K-node graph beats inline token compression.
Unified local AI cost tracker when native dashboards stay siloed and cloud-based.
