AI/ML●●●Banger
Real-time local TTS (31M params, 5.6x CPU, voice cloning, ONNX)
5.6x realtime on CPU with voice cloning beats most local TTS options.
WizardryDark Horse
ZDisket
443mo ago
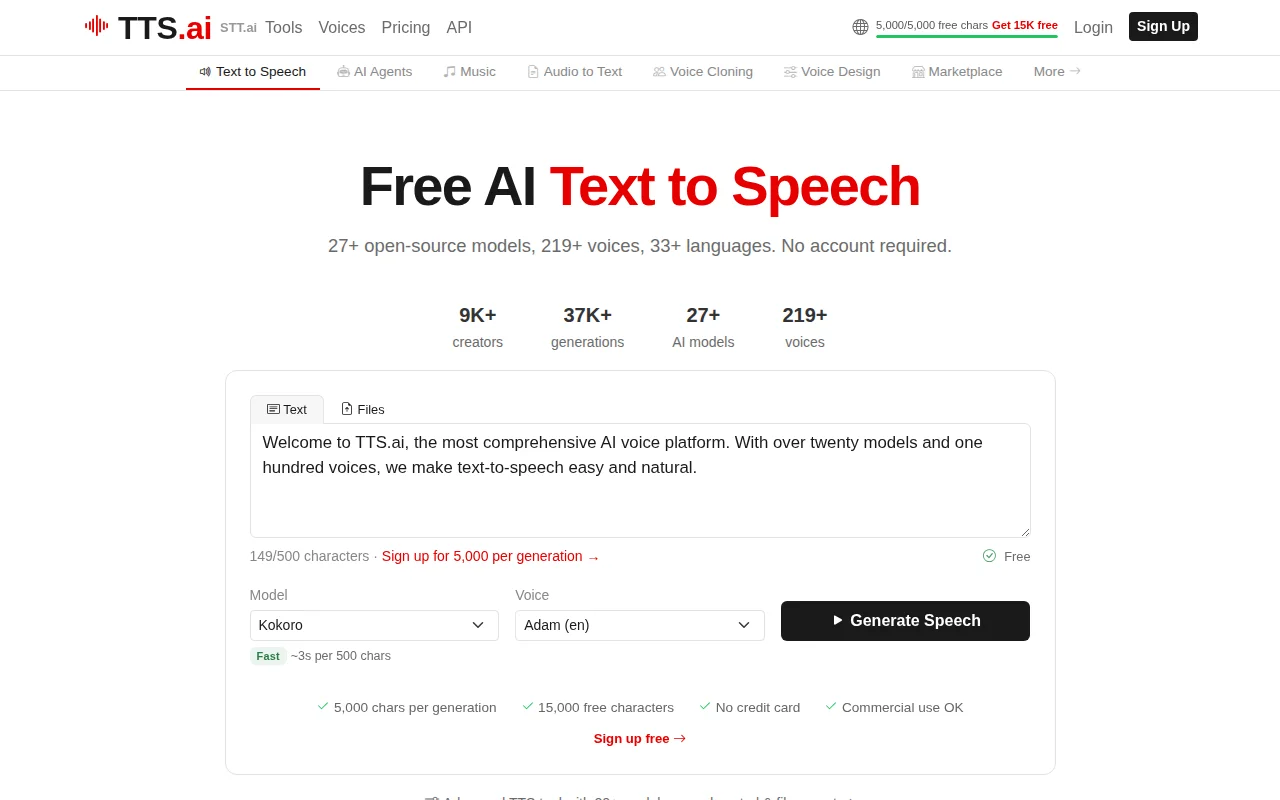
Twenty-seven open-source TTS models in one UI with no signup required for the free tier.
Content creators, developers needing TTS APIs
ElevenLabs · PlayHT · Replicate
5.6x realtime on CPU with voice cloning beats most local TTS options.
Shrinks the usual TTS bloat into a 16MB Electron-alternative wrapper while still letting you clone voices from a short sample and 'design' voices from text prompts. It handles model downloads for you, supports batch exports and macOS auto-updates — smart product trade-offs. Caveat: the app binary is tiny, but the underlying TTS models are downloaded on demand, so expect large model pulls behind the scenes.
Kokoro voice cloning with multilingual support, but voice cloning itself is crowded.
Voice cloning on ESP32 without cloud beats Yoto's subscription model completely.
300M TTS model running locally on consumer GPU or Apple Silicon.
This repo bundles a complete local audio loop — client captures audio, backend transcribes with Parakeet, queries a quantized Mistral LLM via Ollama, then renders speech with Kokoro or Qwen3-TTS for cloning — and reports ~1s round-trip on an RTX5070. It’s a practical, take-it-home demo for running privacy-first voice agents, though it’s still a demo: requires specific tooling (Ollama, GPU headroom), has obvious TODOs (VAD, better warmup for cloning), and isn’t reinventing the architecture.