AI/ML●●Solid
KokoClone – Zero-shot voice cloning using Kokoro TTS
Kokoro voice cloning with multilingual support, but voice cloning itself is crowded.
Niche GemShip It
Ashish106
213mo ago
VITS EVOlution: Lightweight, deployable voice cloning TTS model
5.6x realtime on CPU with voice cloning beats most local TTS options.
ML engineers, developers building offline voice features
Coqui TTS · Piper · StyleTTS 2
The model, with ~31M parameters (ONNX), is tuned for latency and local inference, and comes already exported. I was trying to push the limits of what I could do with small, fast models. Runs 5.6x realtime on a server CPU
It supports voice cloning, voice blending (mix two or more speakers to make a new voice), the license is Apache 2.0 and it uses DeepPhonemizer (MIT) for the phonemization, so no license issues.
The repo contains the checkpoint, how to run it, and links to Colab and HuggingFace demos.
Now, because it's tiny, audio quality isn't the best, and as it was trained on LibriTTS-R + VCTK (both fully open datasets), speaker similarity isn't as good.
Regardless, I hope it's useful.
Kokoro voice cloning with multilingual support, but voice cloning itself is crowded.
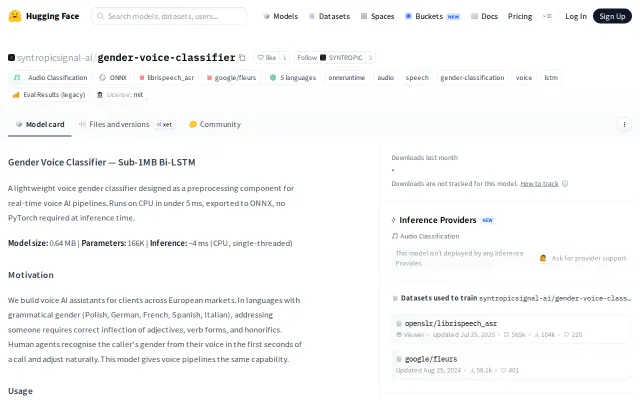
Enables grammatical gender inflection in EU voice agents with 4ms CPU inference.
Sub-sentence TTS streaming beats Piper/Sherpa-ONNX latency by token-level triggering on CPU.
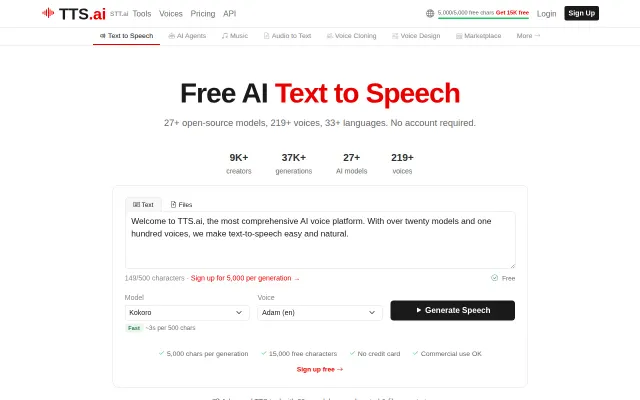
Twenty-seven open-source TTS models in one UI with no signup required for the free tier.
Shrinks the usual TTS bloat into a 16MB Electron-alternative wrapper while still letting you clone voices from a short sample and 'design' voices from text prompts. It handles model downloads for you, supports batch exports and macOS auto-updates — smart product trade-offs. Caveat: the app binary is tiny, but the underlying TTS models are downloaded on demand, so expect large model pulls behind the scenes.
SOTA expressivity at 14M parameters beats cloud models for on-device TTS.