AI/ML●Mid
I benchmarked Gemma 4 E2B – the 2B model beat the 12B on multi-turn
2B model beats 12B on some tasks, saving hardware costs for edge deployment.
Big BrainNiche Gem
mailharishin
813mo ago
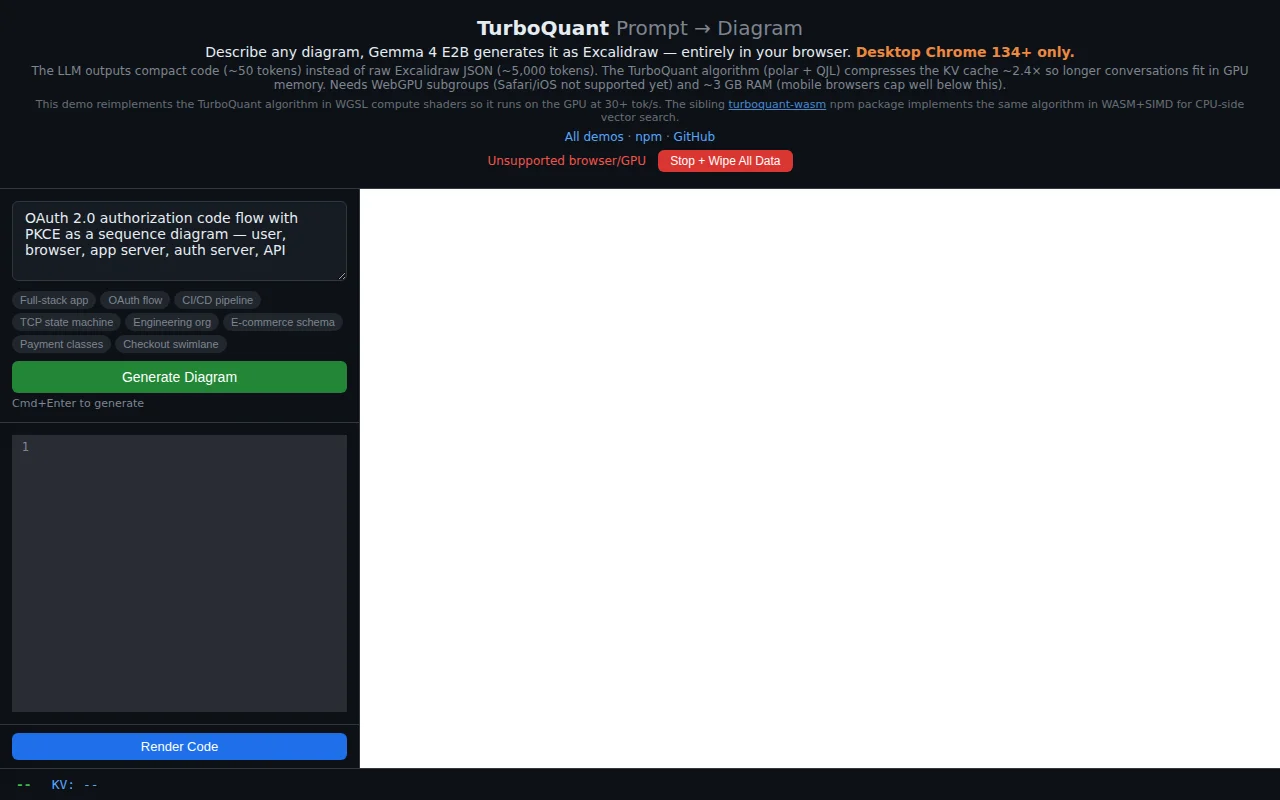
50-token compact code output beats raw 5,000-token Excalidraw JSON — clever compression.
Frontend developers, ML engineers interested in edge inference
WebLLM · Transformers.js · MLC Chat
2B model beats 12B on some tasks, saving hardware costs for edge deployment.
Runs Gemma 4 E2B and Kokoro TTS locally with barge-in and vision.
WebGPU-powered Gemma 4 demo brings local inference to a standard agent architecture explainer.
Local LLM agent with DOM tools running entirely in-browser via WebGPU.
Basic canvas demo when Chrome's own docs already cover this API.
Milkdrop running in the browser via WebGPU is pure nostalgia fuel.
![Milkdrop Visualizations with WASM+WebGPU [TW: flashing lights]](/screenshots/47965960_thumb.webp)