AI/ML●●●Banger
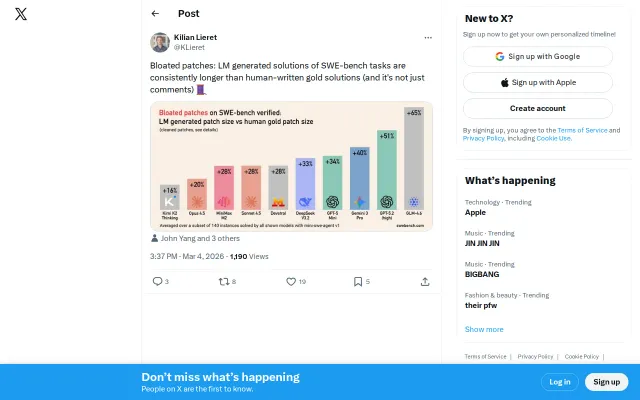
97% on SWE-bench Verified with subscription-token agents
97% on SWE-bench Verified with full artifact transparency, not just a score claim.
Big BrainZero to One
kimjune01
2019d ago
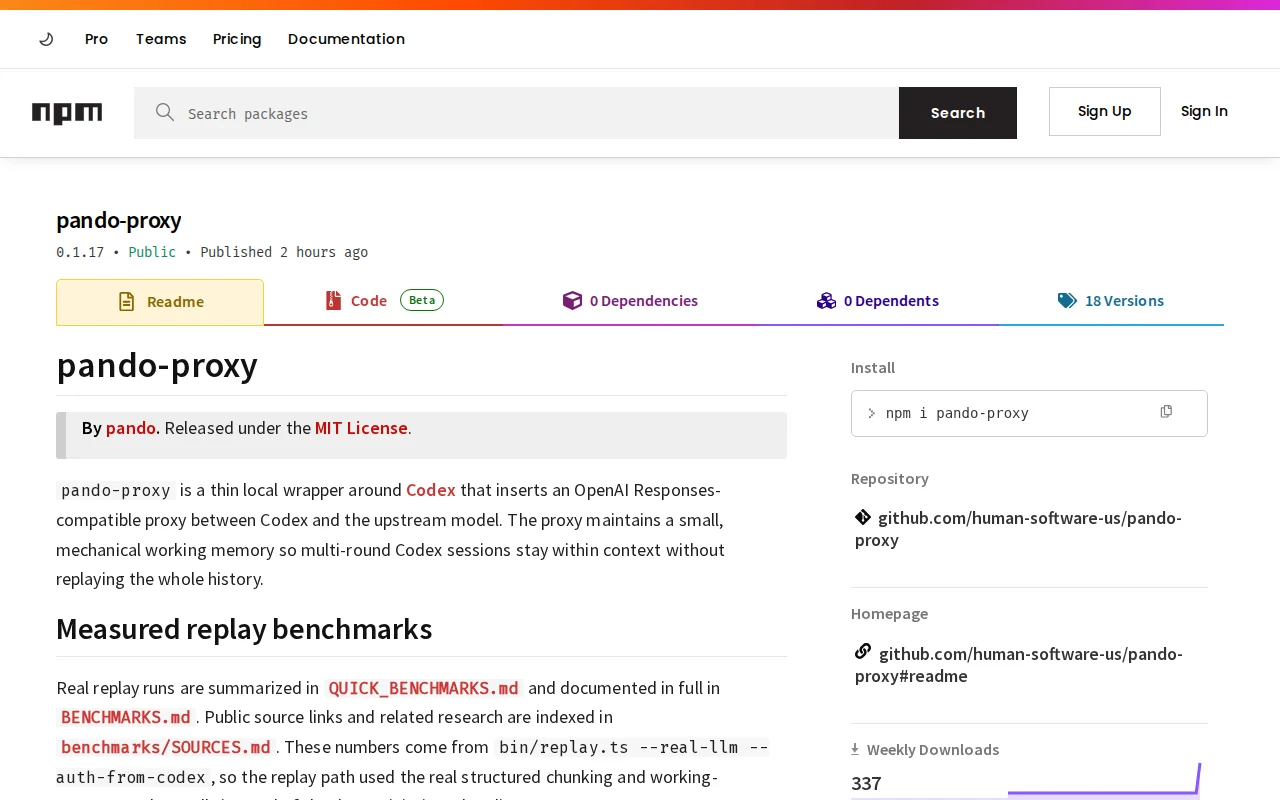
Transparent proxy cuts Codex context tokens by 87% via working memory.
Developers using OpenAI Codex for software engineering tasks
Cursor · Continue · LangChain Memory
Here's what I did:
1. Built a proxy that intercepts Codex's calls to OpenAI and rewrites them on the fly.
2. Replayed 3,807 rounds of SWE-bench Verified traces through it: avg prompt 44k → 6k tokens (-87%).
3. Posted it to HN to get the next reduction applied to my confidence interval — starting with the inevitable "How about accuracy?"
npx -y pando-proxy · github.com/human-software-us/pando-proxy
97% on SWE-bench Verified with full artifact transparency, not just a score claim.
Twitter thread with a chart; not a product or tool.
Chrome DevTools for Claude Code sessions when LangSmith drops local tool calls.
Fault-localization scaffolding for AI agents; claims 93% top-5 recall, but Cursor/Cline already integrate similar.
Finally, a tool that tells you why your AI coding bill is exploding.
They split responsibilities across isolated agents (engineer, reviewer, manager) that get real shell access and independent filesystems, which makes failures traceable and lets you tune model capacity per role. Hitting 72.2% on SWE-bench Verified with no benchmark-specific tuning is an impressive empirical result — interesting architecture and strong evidence — though the security and long-term reliability of autonomous shell-executing agents remain the big open questions.