AI/ML●●●Banger
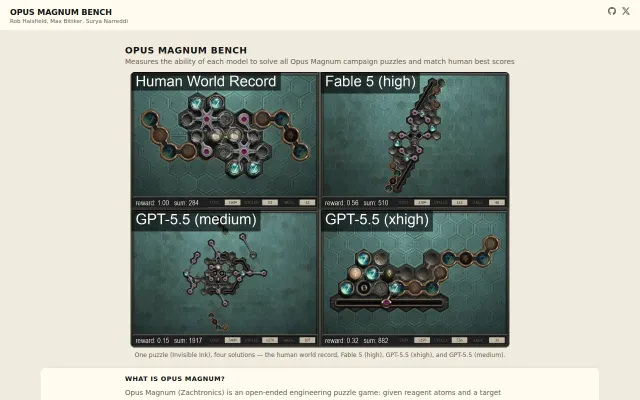
Opus Magnum Bench -- Shape Rotation and Alchemical Engineering
Game-based AI benchmark measuring spatial reasoning against human speedrun records.
Big BrainNiche Gem
ClassicRob
3027d ago
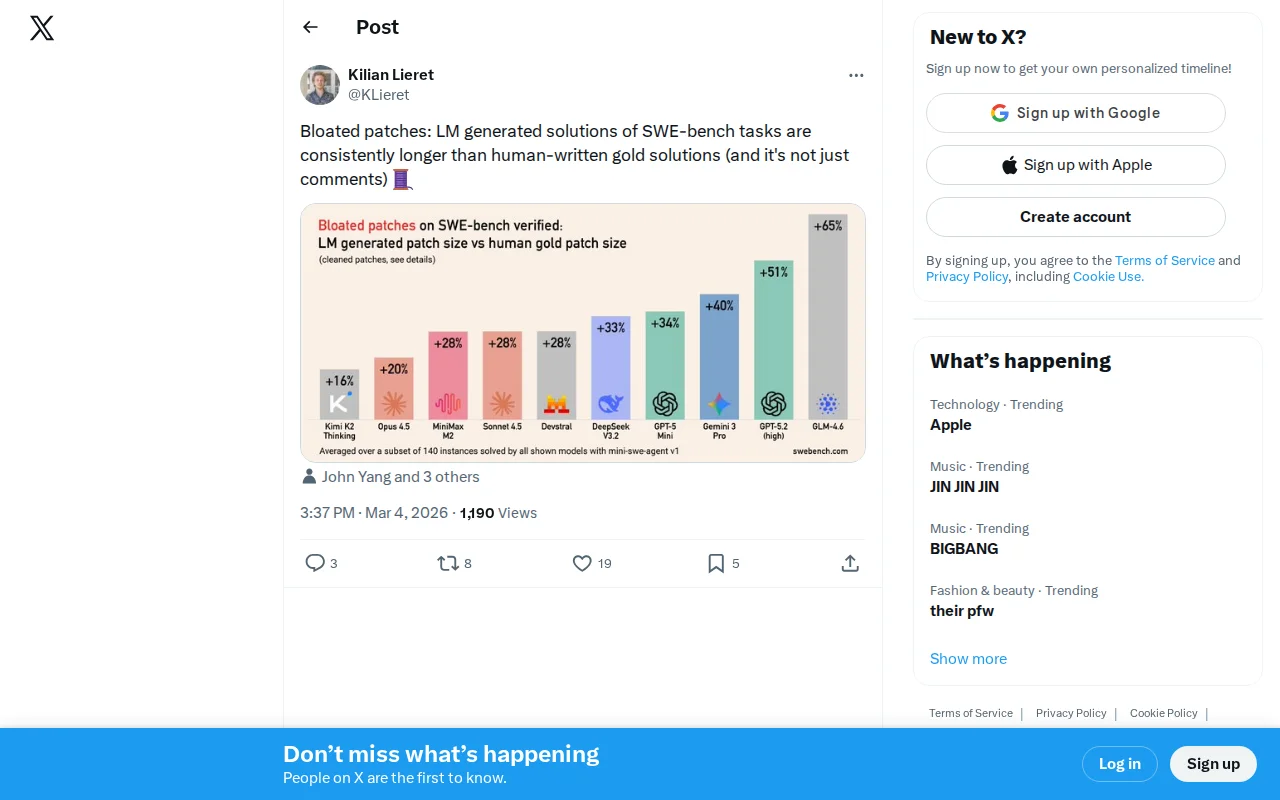
Twitter thread with a chart; not a product or tool.
AI researchers, ML practitioners studying code generation models
Game-based AI benchmark measuring spatial reasoning against human speedrun records.
Pre-registered methodology shows 17/50 wrong fixes ungated vs 0/50 gated, but the actual tool is private.
Transparent proxy cuts Codex context tokens by 87% via working memory.
Multilingual tokenization comparison across Arabic, Chinese, French that LangSmith ignores.
97% on SWE-bench Verified with full artifact transparency, not just a score claim.
Beats humans at pronunciation scoring but doesn't ship product integration yet.