AI/ML●●●Banger
LOAB – AI agents get decisions right but skip the process [pdf]
Frontier models hit 67-75% outcome accuracy but only 25-42% on process compliance.
Big BrainBold Bet
shubh-chat
103mo ago
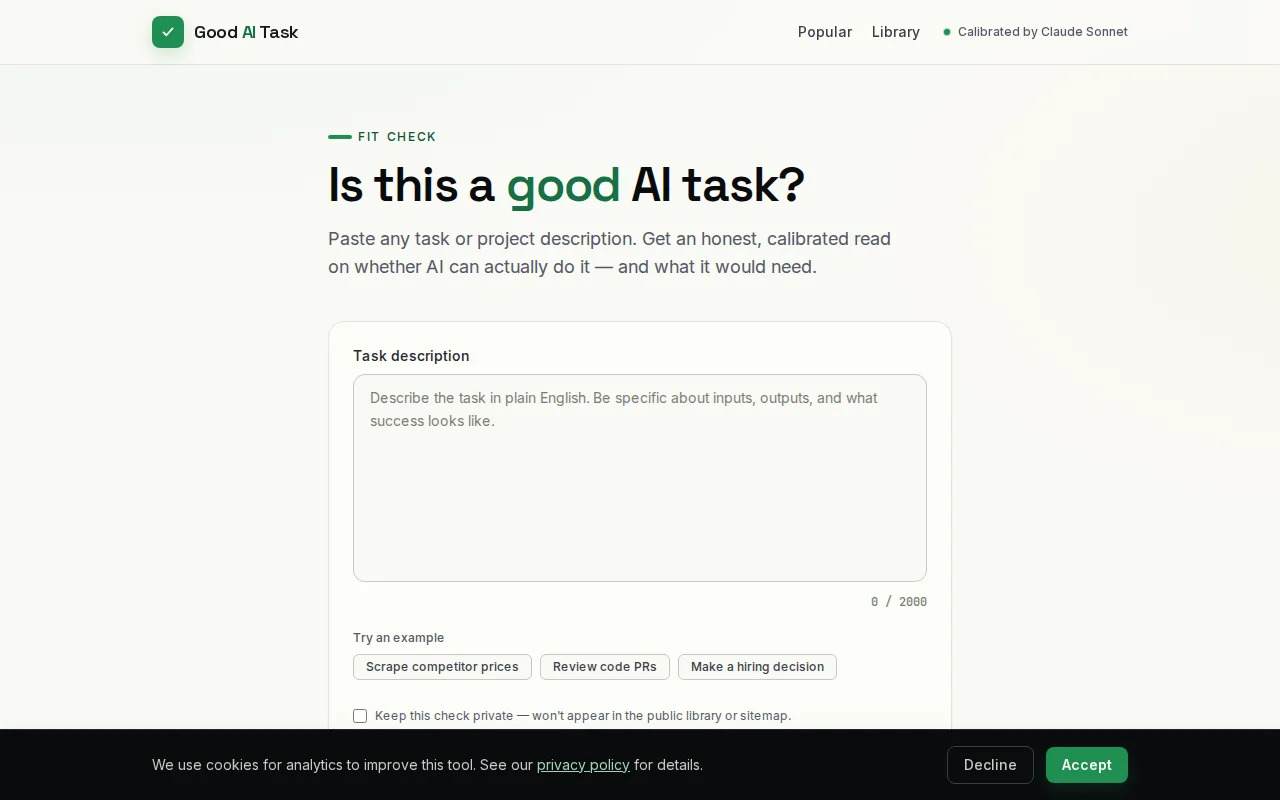
Five-dimension framework tells you when AI will fail before you waste hours prompting.
People deciding whether to use AI for specific tasks
The most fun use is testing it on things you already know it can't do and seeing how it explains why it can't be done.
Frontier models hit 67-75% outcome accuracy but only 25-42% on process compliance.
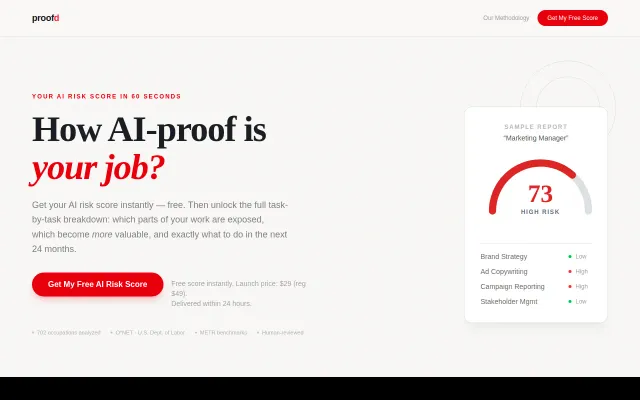
Task-level AI risk beats job-title predictions, but methodology isn't transparent.
Fourteen parallel Claude agents grade your startup idea's evidence before you quit your job.
Six-dimension scoring framework beats guesswork for improving Claude Code skills.
Yet another JD analyzer, but the roast branding makes it shareable.
Six-dimension scoring for Claude skills when nothing else measures quality this way.