AI/ML●●Solid
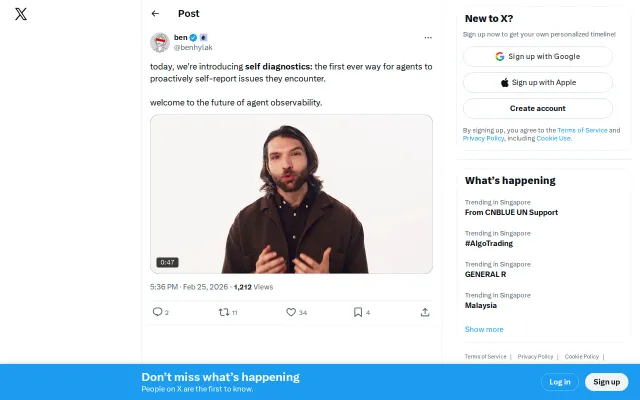
Nexa-Gauge – LLM eval framework, now with self-hosted model support
Cache-aware LLM eval with self-hosted model support beats Ragas on flexibility.
Solve My ProblemSlick
Sardhendu
202mo ago
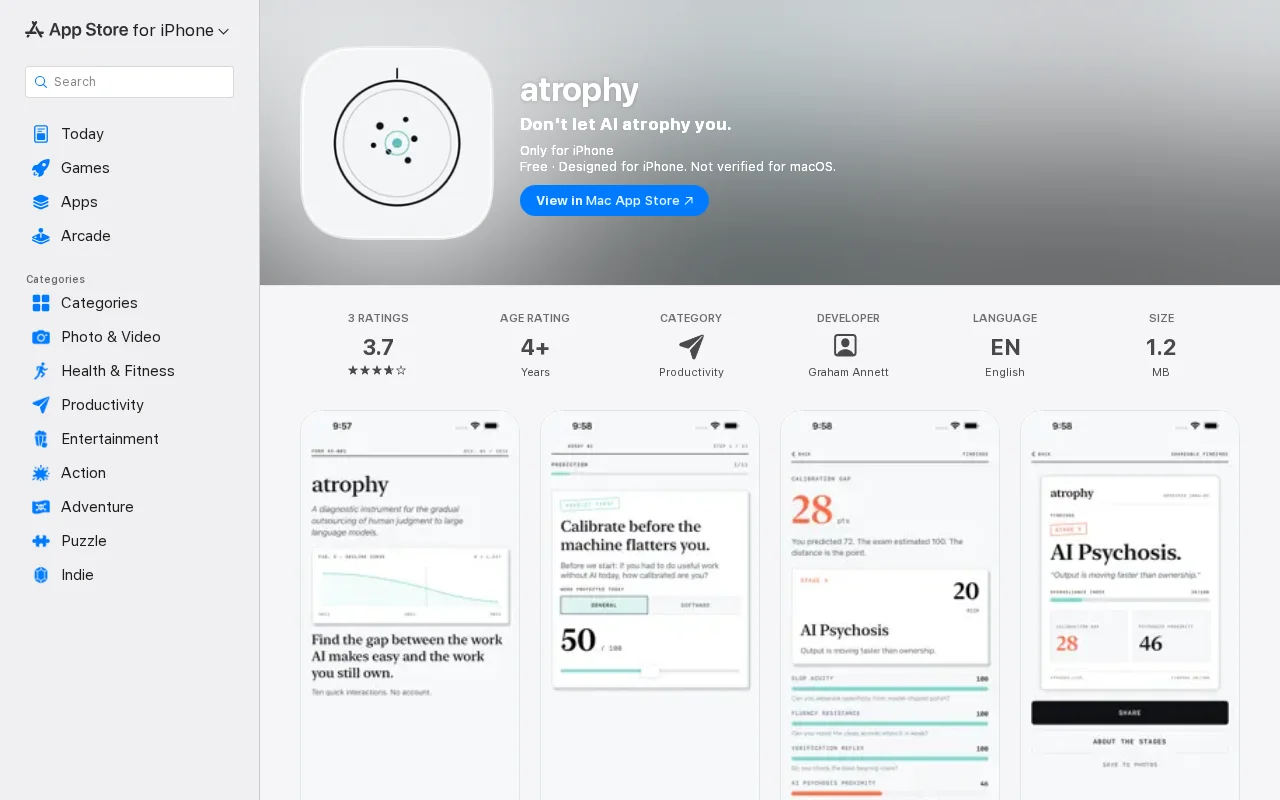
Self-reported quiz data can't actually measure cognitive atrophy.
Software engineers worried about AI dependency
Screen Time · RescueTime
I built it because I noticed a pattern: formerly AI-skeptical coworkers now open every standup or design discussion with "I asked Claude..." or "Claude told me..." for technical problems and design decisions. I've felt the same pull myself to delegate every task or problem to AI. It's easy to lean on these tools for almost any amount of critical thinking or problem solving, and I'm worried about what it means when knowledge workers atrophy their cognition this way.
I'm not anti-AI nor do I think these models will completely replace software engineers. But as long as humans are still in the loop for software engineering, I don't have a good answer for how to avoid becoming overly reliant on these models. How do we gauge how over-reliant we've become, or maintain responsibility for the programs and systems we ship while outsourcing 90% of the judgment we used to be required to make? How do we learn what good code looks like when PR size and velocity have grown to the point that only the important parts get reviewed?
I'm hoping to work on better ways to notice this pattern and practice our way back from it. This is my first attempt (offline only, no accounts/analytics).
Cache-aware LLM eval with self-hosted model support beats Ragas on flexibility.
Agent self-reporting is clever, but the X post lacks proof or actual product details.
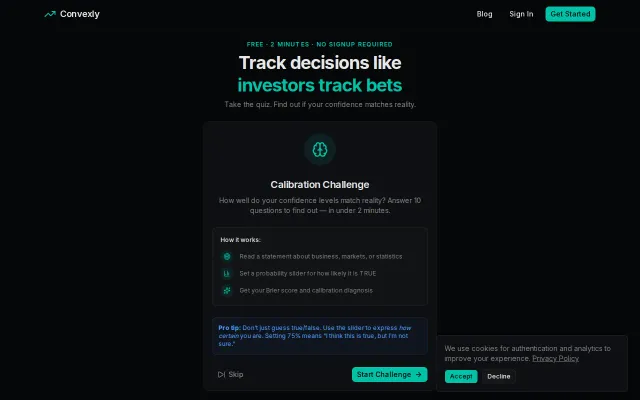
Brier score calibration quiz is solid but prediction tracking tools already exist.
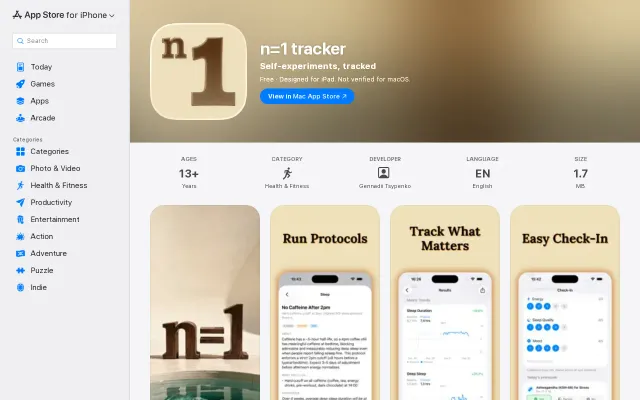
Curated protocol library with falsifiable hypotheses beats generic habit trackers.
Reports + dashboards + distribution in one place, but oversells against entrenched BI stacks.
Self-hosted simulator streaming beats BrowserStack on privacy and recurring costs.