Infrastructure●Mid
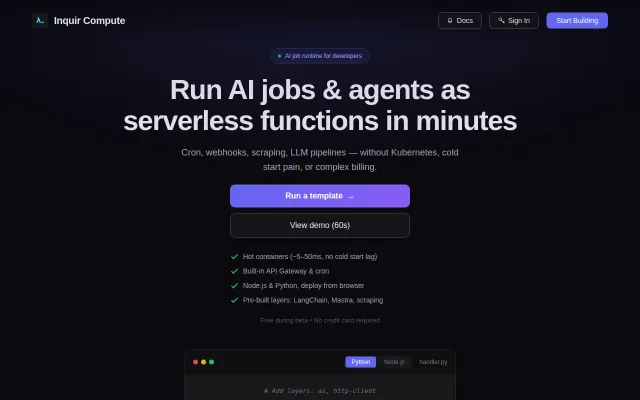
I have created my own serverless lambda service
Hot containers at 5-50ms compete with Vercel and AWS Lambda on their turf.
Ship ItBold Bet
nenecmrf
104mo ago
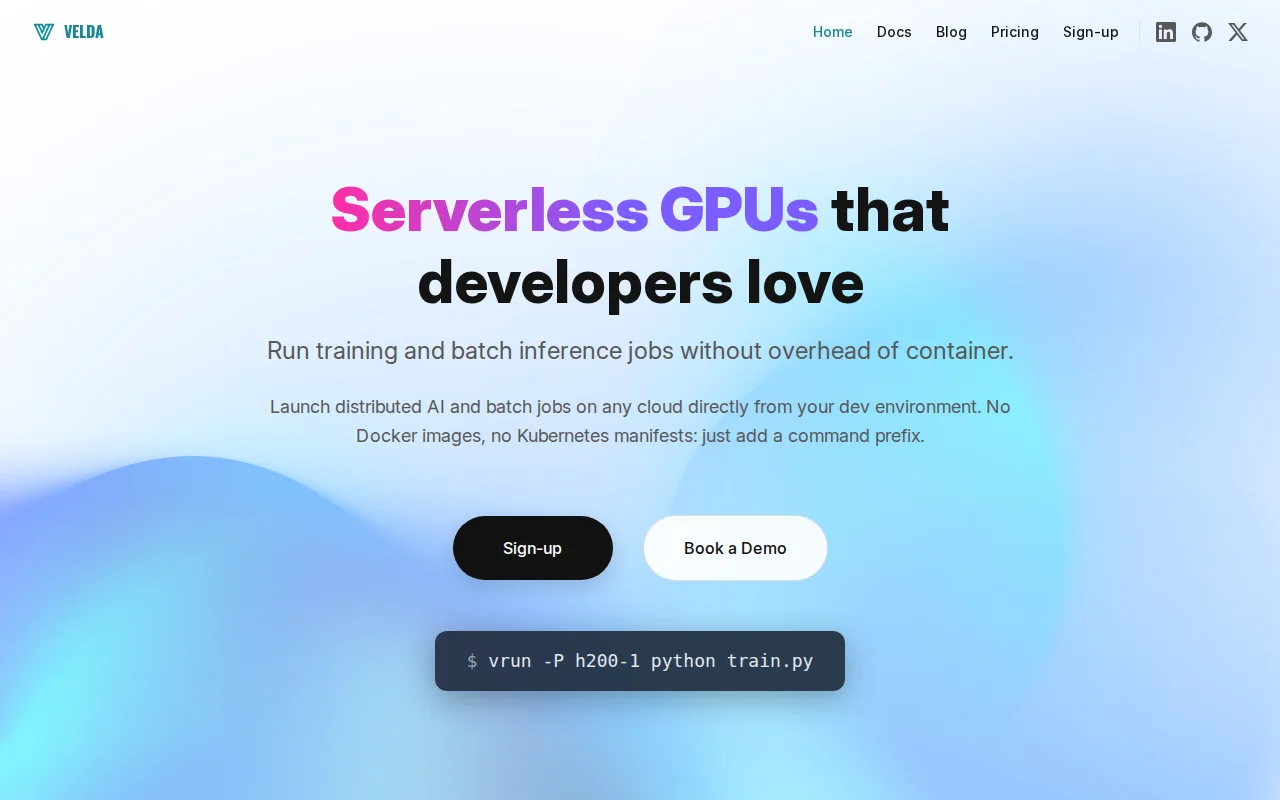
Custom streaming filesystem beats Docker pull times for instant GPU job startup.
ML engineers and data scientists running training jobs
Modal · RunPod · SkyPilot
We believe containers create too much overhead during development. We built Velda to let you launch jobs directly in the cloud by mirroring your Velda managed dev-environment, all with just a command prefix. That way, you only need to allocate GPUs when you're running your training jobs, with no change to your workflow.
How it works:
* No manifests or custom libraries: You don't need to rewrite your code or define YAML. Just prefix your command with vrun.
* Zero Restrictions: Use any tool, binary, or library already on your machine.
* Instant Launch: We built a custom streaming file system. Instead of waiting for a 5GB image to pull, we stream only the necessary bits to the cloud instance, allowing jobs to start in seconds after the machine boots.
The core is open source: https://github.com/velda-io/velda and can be deployed on AWS/GCP/Nebius
If you want to try the hosted version, we’re giving free credits for your first GPU jobs: https://cloud.velda.io
Hot containers at 5-50ms compete with Vercel and AWS Lambda on their turf.
Finally ties GPU metrics to actual workloads when DCGM only gives you uuids.
REAPI-compatible distributed compute without Docker, etcd, or third-party Raft.
Collapses Docker, containerd, and Firecracker into one 12MB binary with zero-copy storage.
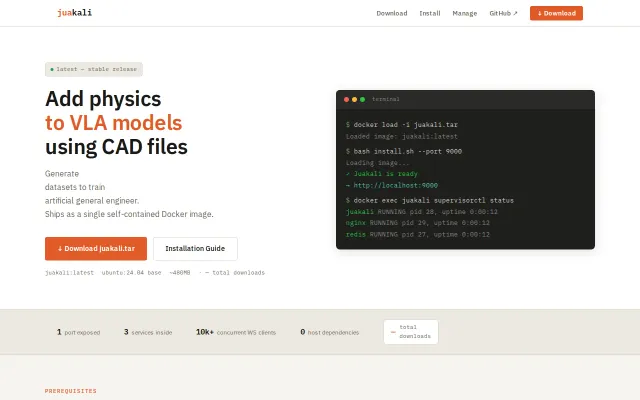
Assembly-specific physics simulation for VLA training when Isaac Sim exists for general robotics.
OCI-based agent skill packaging, but limited adoption and niche audience versus established agent frameworks.