Security●●●Banger
Rampart v0.5 – what stops your AI agent from reading your SSH keys?
Two-command setup blocks prompt-injected shell commands before they execute, not after.
Solve My ProblemZero to One
trevxr
103mo ago
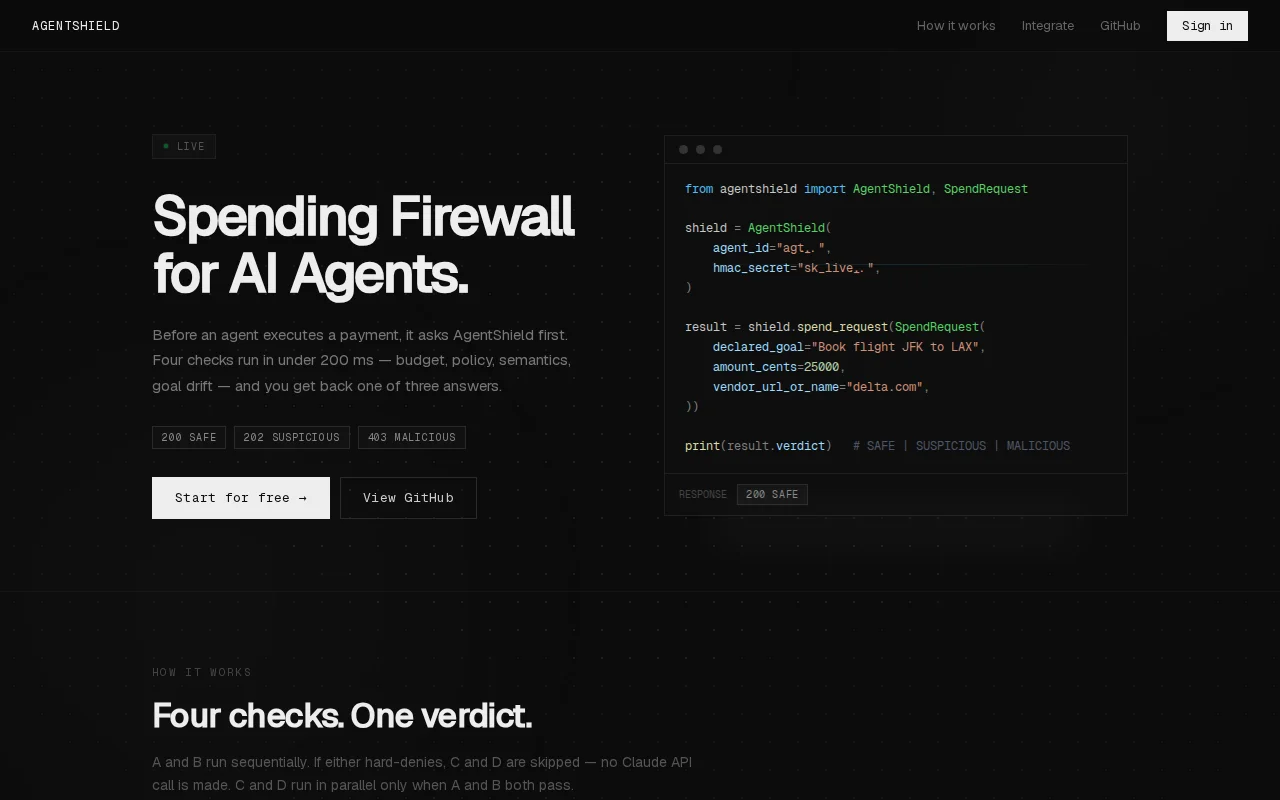
Four-check firewall stops rogue agents before they drain your wallet.
Developers building autonomous AI agents with payment capabilities
LangChain Guardrails · Lakera Guard
Every spend request runs through four checks before money is allowed to move:
1. Quantitative (Redis) - Is the agent within its daily budget? Is it sending the same transaction over and over?
2. Policy (Postgres) - Is the vendor blocked? Is the amount too high to auto-approve? Is the stablecoin/network/address allowed?
3. Semantic (Claude Haiku) - Does the stated goal actually match what's being purchased?
4. Goal Drift (Claude Haiku) - Is this purchase within what the agent is supposed to be doing at all?
Checks 1 and 2 run sequentially — if either hard-denies, Claude never gets called. Checks 3 and 4 run in parallel via asyncio.gather.
One verdict comes back: SAFE, SUSPICIOUS, or MALICIOUS.
Full product — live dashboard, auth, HITL approval flows, spend monitoring. Completely free.
Looking for feedback, especially from anyone running spending agents in production.
Landing page: https://agentshieldv2-dashboard-production.up.railway.app
Two-command setup blocks prompt-injected shell commands before they execute, not after.
1921 electrical engineering oscillator math stops AI loops at convergence.
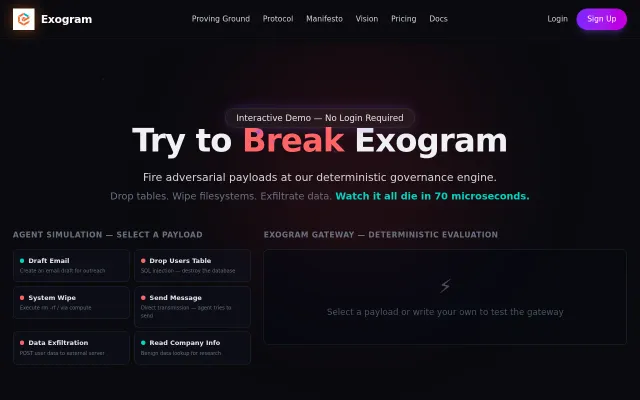
Deterministic policy gates beat LLM guardrails when your agent tries to DROP TABLE.
Yet another ad spec checker in a category platforms already solve themselves.
Hard budget kill-switch stops runaway agent costs before the bill hits.
Blocks terraform destroy and git push before agents execute destructive commands.