Productivity●Mid
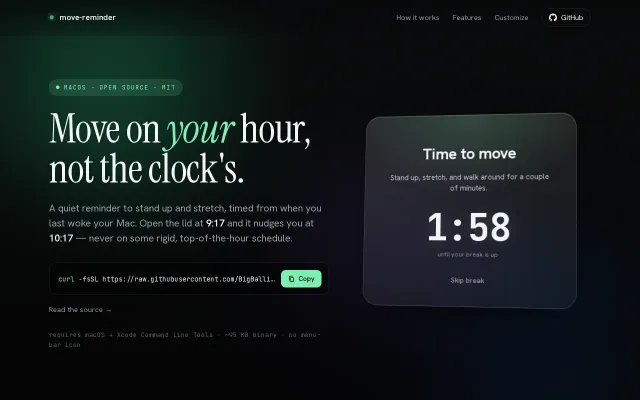
Pomota – Pomodoro timer that forces breaks (Tauri, Rust+React)
Another Pomodoro timer, but this one forces you to stop working.
Cozy
heliskyr2
202mo ago
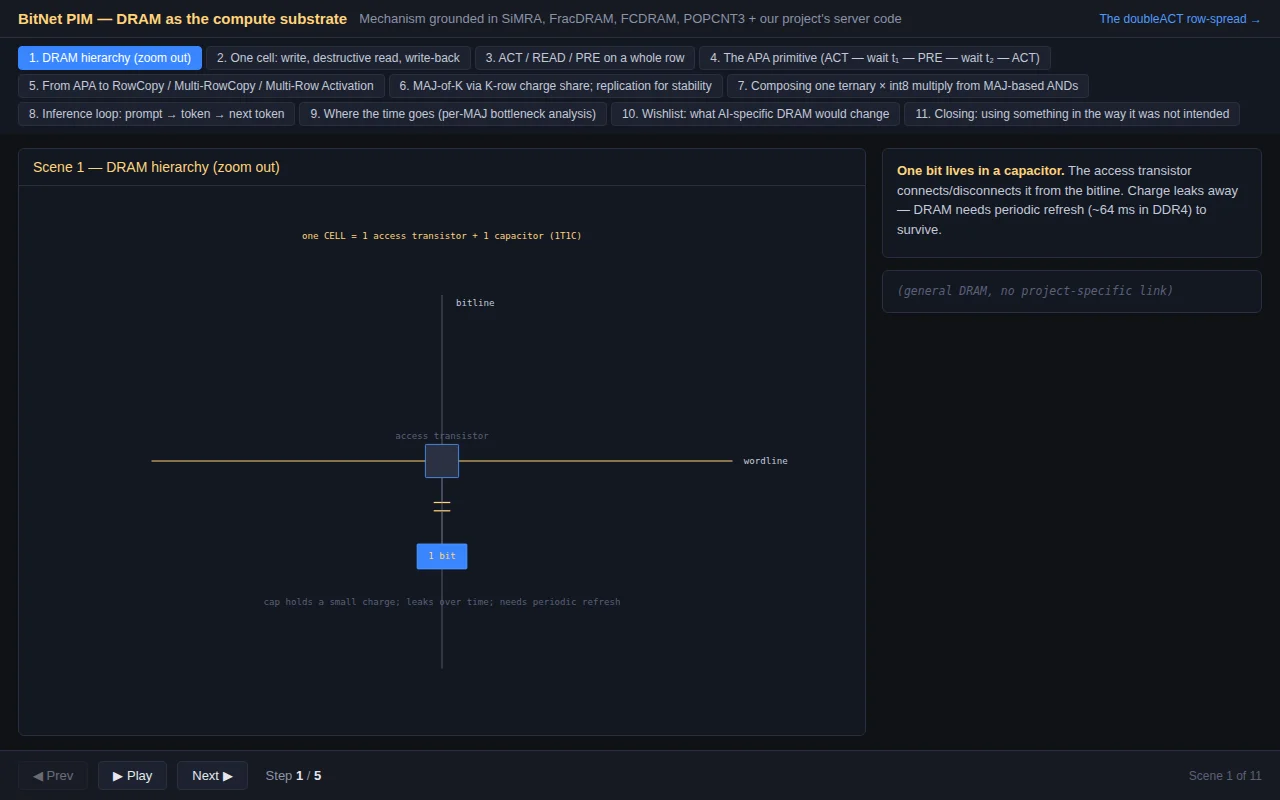
Running AI inference by breaking DDR4 timing rules on off-the-shelf memory is wild.
Computer architects, hardware researchers, low-level systems engineers
Upmem PIM · Samsung HBM-PIM · Mythic AI
Another Pomodoro timer, but this one forces you to stop working.
16-24x faster RAG iteration via shard-based concurrent execution with live control.
Wake-anchored timing means breaks never interrupt your flow state.
Flexible phase switching is nice, but dozens of Pomodoro apps already do this.
Fills the TypeScript gap that Semgrep's official AI best practices pack misses.
Privacy-first break reminder, but Time Out and Stretchly already do this better on desktop.