Infrastructure●●●Banger
ZSE – Open-source LLM inference engine with 3.9s cold starts
3.9s cold starts vs 45s+ for quantized models—real infra pain solved tangibly.
WizardrySolve My Problem
zyoralabs
5893mo ago
E8 lattice codebook quantization for LLM weights — 2/3/4 bpw with fused Triton inference kernel
E8 lattice codebooks beat GPTQ at 2-4 bpw with fused CUDA kernel skipping weight materialization.
ML engineers running LLMs on memory-constrained GPUs
GPTQ · QuIP# · AWQ
Glq is effective compared to other LLM quantization algorithms at between 2-bits per weight up to 4 bits per weight. The effectiveness of glq at low bits per words is due to the properties of the E8 lattice compared to linear methods. Glq also supports mixed precision quantization where different LLM layers uses different compression bit weight depending on how sensitive the LLM layers are to quantization. Think of mixed precision a bit like MP3 or MP4 variable bit rate encoding.
I currently develop glq using g7e AWS spot instances to keep the cost more reasonable.
Glq uses vllm
4 bit Key value cache by E8 was inspired by NexusQuant. I try and squeeze in about four times as much Key value cache as normally would fit by BF16 in VRAM, or about two times compared to INT8.
I somehow wrongly at start picked a E8 code book size of 65536 entries instead of 4096 code book entries which better fits in GPU L1 cache. Having 65535 code book entries it turns out leads to higher LLM compression rate but at trade of of decode speed. I am trying to compensate by using Nvidia Cuda graphs and optimize the decode, currently work in progress.
To install glq in a python virtual environment on Linux with a Nvidia GPU: pip install glq
Python PIP package https://pypi.org/project/glq/
Glq source code. https://github.com/cnygaard/glq
Current PC RAM Prices that inspired the library. https://pcpartpicker.com/trends/price/memory/
https://en.wikipedia.org/wiki/E8_lattice Eight dimensional lattice that provides optimal solution to the sphere packing problems. Think about it a bit like stacking cannon balls or stacking apples in an optimal way. Only you swap the apples for LLM weights.
Picture of an E8 lattice https://en.wikipedia.org/wiki/E8_polytope#/media/File:E8_gra...
Credits: GLQ was inspired by E8 Quip# and Key value E8 compression was inspired by NexusQuant.
Math: The sphere packing problem in dimension 8, Maryna Viazovska https://arxiv.org/abs/1603.04246
4bpw glq Quantization of Gemma 4 E4b-instruction tuned https://huggingface.co/xv0y5ncu/Gemma-4-E4B-it-GLQ-4bpw
3.5bpw mixed precision quantization of SmolLM3 https://huggingface.co/xv0y5ncu/SmolLM3-3B-GLQ-3.5bpw
Docker image of glq on Nvidia GPU with Nvidia container toolkit. docker run --rm --gpus all \ -v "$HOME/.cache/huggingface:/cache/hf" \ ghcr.io/cnygaard/glq-env:0.5.0 \ python -c ' import glq.hf_integration, torch # registers GLQ with HF from transformers import AutoModelForCausalLM, AutoTokenizer mid = "xv0y5ncu/SmolLM3-3B-GLQ-3.5bpw" tok = AutoTokenizer.from_pretrained(mid) model = AutoModelForCausalLM.from_pretrained( mid, device_map="cuda", torch_dtype=torch.float16) ids = tok("The capital of France is", return_tensors="pt").to("cuda") print(tok.decode(model.generate(*ids, max_new_tokens=20)[0], skip_special_tokens=True)) '
Currently work in progress on glq in getting the decode speed up and supporting more LLM model architectures.
Open question, Does glq work on Nvidia DGX spark and gaming Nvidia hardware such as 4070-5090?
3.9s cold starts vs 45s+ for quantized models—real infra pain solved tangibly.
Deterministic fingerprinting for model structure without loading weights.
Home rig for attribute-weighted benchmarking lacks the polish of established eval frameworks.
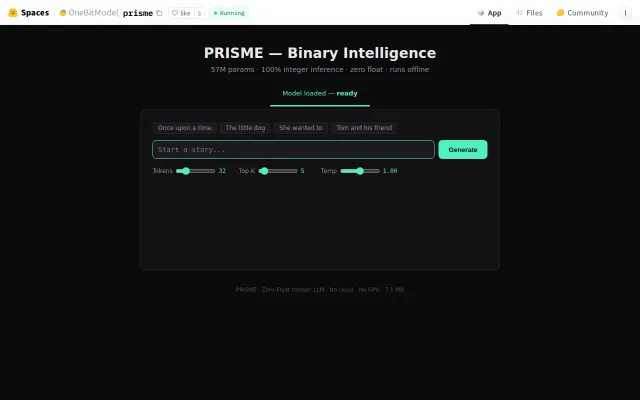
7MB binary-weight LLM runs entirely on integer math with no floating point unit.
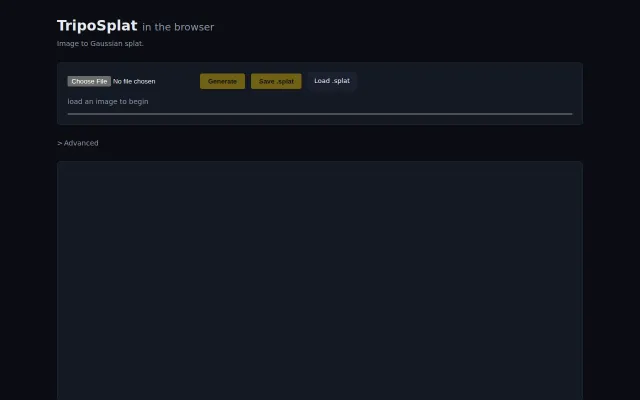
Quantized Gaussian splatting running entirely in browser with no server.
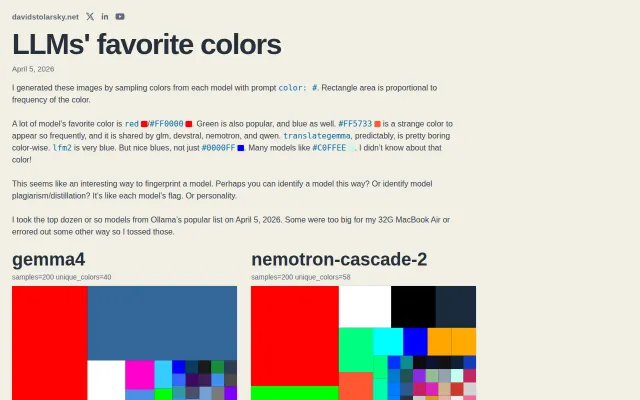
Sampling hex codes from 10 LLMs exposes bias patterns useful for fingerprinting.
{kind=link}