AI/ML●●Solid
Running Gemma 4 on an iPhone 13 Pro
Clean Swift wrapper for Gemma 4 with vision and audio on iPhone.
Niche GemShip It
dengjiuhong
103mo ago
Neutral, reproducible benchmark for local LLMs on Apple Silicon (Mac · iPhone · iPad) — MLX, llama.cpp, CoreML, Apple Foundation Models
LiteRT beats MLX on Gemma memory while CoreML sips power on the Neural Engine.
iOS AI developers, Edge ML engineers
MLC Bench · Llama.cpp Benchmarks · Perfetto
Clean Swift wrapper for Gemma 4 with vision and audio on iPhone.
LLM mutates the workflow DAG mid-run via a constrained four-verb grammar.
VRAM calculator with crowd-sourced tok/s benchmarks when model cards already exist.
First standalone Apple Watch LLM app running 700M-1.7B models completely offline.
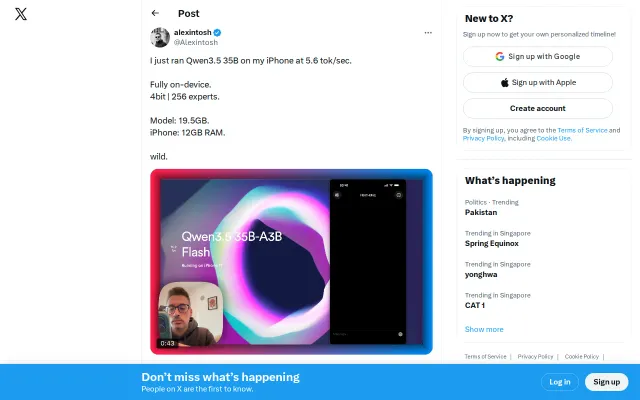
Runs 19.5GB Qwen3.5 on 12GB RAM iPhone via memory swapping.
Mobile SSH plus AI agent deployment when Termius already handles SSH.