AI/ML●●Solid
Qwen3.6-35B-A3B on a 16 GB M1 Pro with SSD-streamed MoE
SSD-streamed MoE lets 16GB M1s run 35B models, but it's a specialized fork of antirez's ds4.
Big BrainNiche Gem
andreaborio
24412d ago
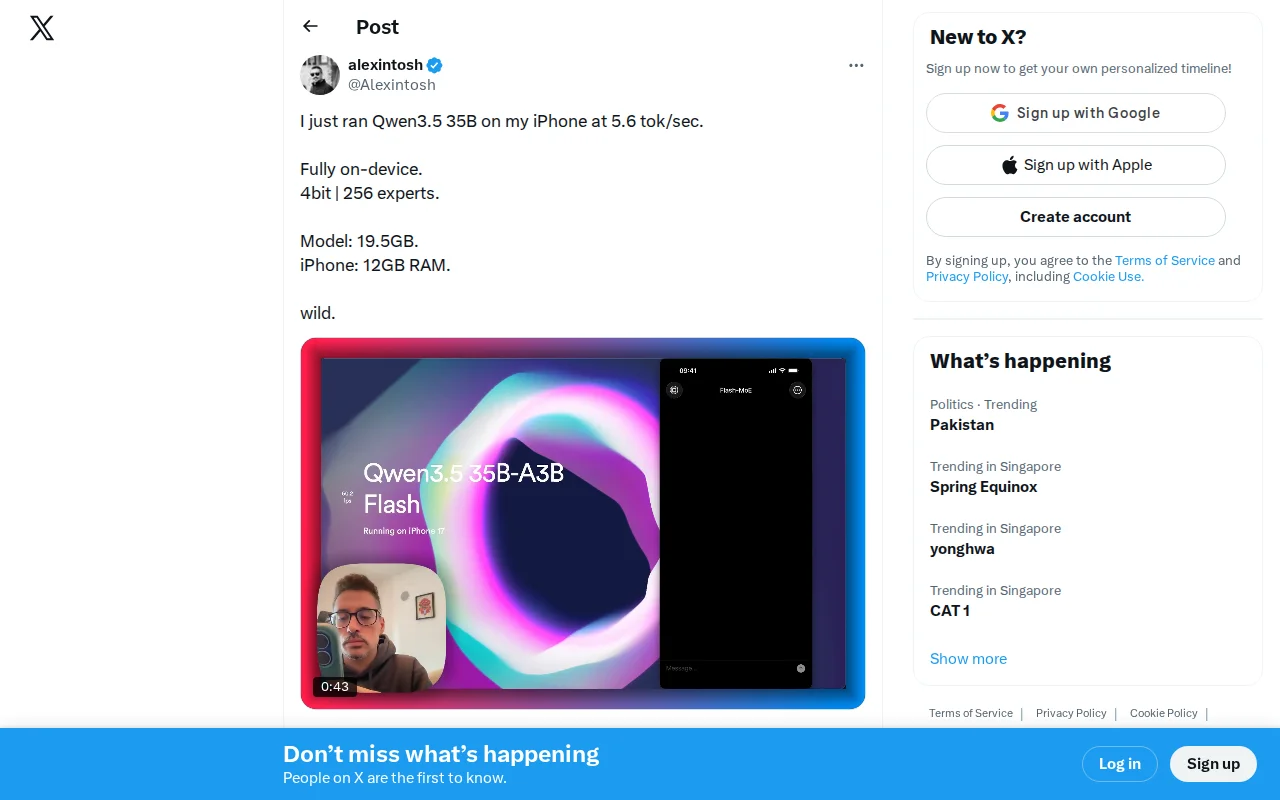
Runs 19.5GB Qwen3.5 on 12GB RAM iPhone via memory swapping.
Mobile AI developers, quantization enthusiasts
MLC LLM · llama.cpp
SSD-streamed MoE lets 16GB M1s run 35B models, but it's a specialized fork of antirez's ds4.
Clever hardware hack but this is a config guide, not a shipped tool.
Fits a 35B MoE model into 16GB RAM by running entirely on CPU without GPU acceleration.
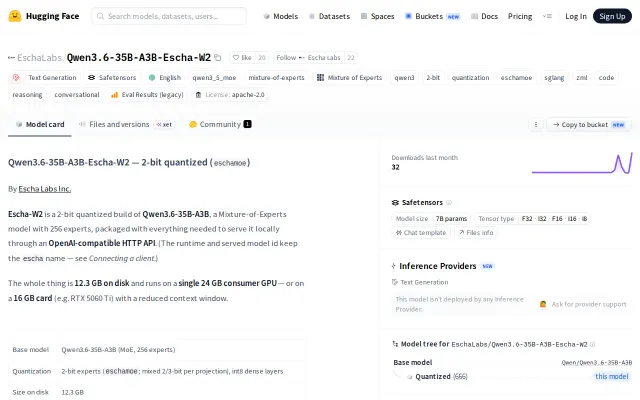
Runs a 35B MoE model on 24GB VRAM with 2-bit quantization and minimal quality loss.
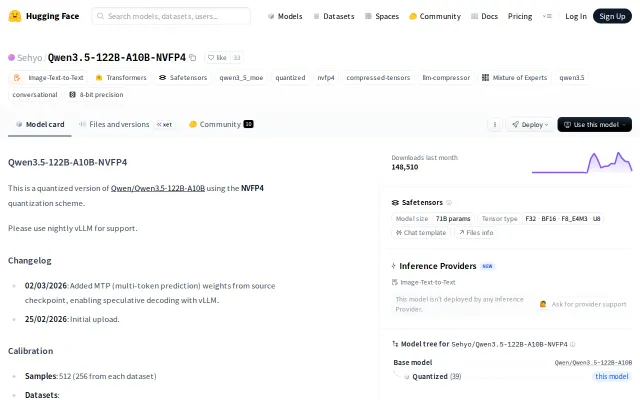
Bypasses NVIDIA's artificial FP4 lock—122B MoE on single desktop GPU at 31 tok/s.
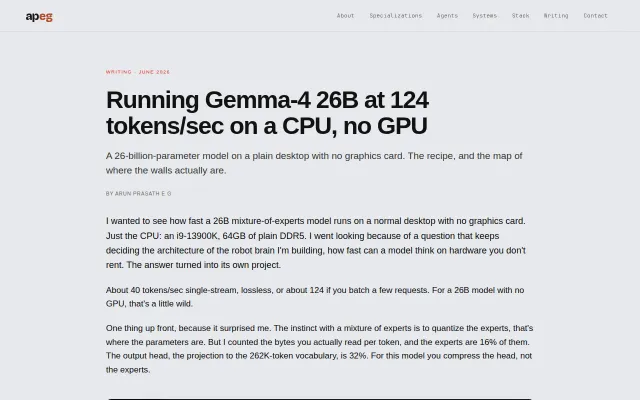
26B model at 124 tok/s on CPU by compressing the output head, not the experts.