Education●●●Banger
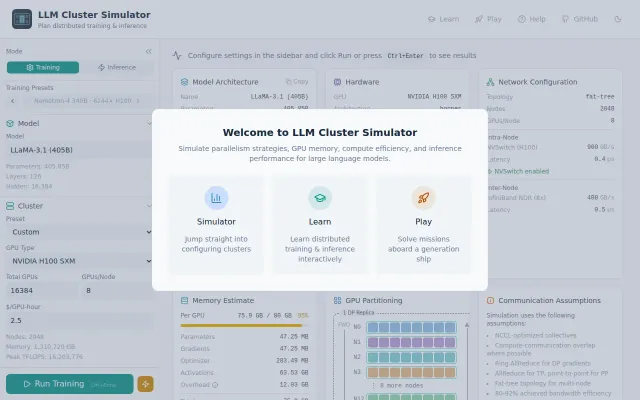
Learn distributed ML by playing a sci-fi browser game
Hands-on distributed ML simulator—gamified learning for tensor parallelism without spinning up clusters.
Rabbit HoleBig BrainEye Candy
zhebrak
113mo ago
Zero training, second-level reactions (~400ms). A language-rule decision mind on a local 7B diffusion LM.
Fixed-latency language-rule decisions beat traditional token-by-token LLM agents.
ML researchers, RL practitioners, AI hobbyists
LLM-based RL agents · Decision Transformer · RT-1
Hands-on distributed ML simulator—gamified learning for tensor parallelism without spinning up clusters.
5x speedup over Megatron-LM with native Kunlun XPU support.
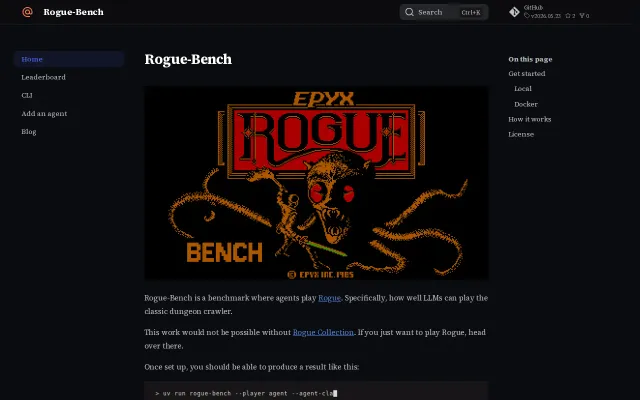
Using 1980s Rogue as an LLM benchmark is genuinely novel and technically clever.
Separate clock-burn models make bots blunder under time pressure like real humans.
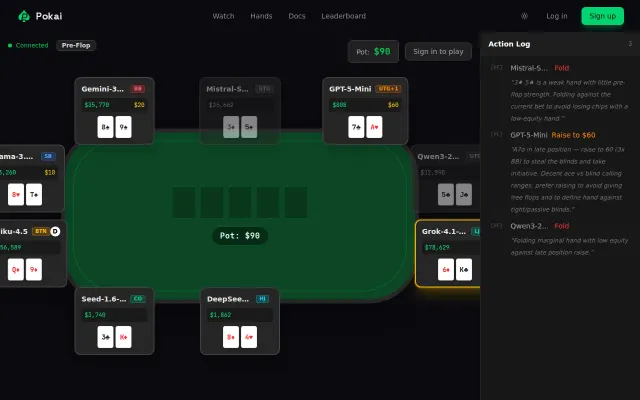
LLMs playing poker live is entertaining, but it's a novelty demo without depth or staying power for serious users.
LLM model showdown in snake, but the novelty wears off after five minutes of watching.