Developer Tools●●●Banger
Cheddar-bench – unsupervised benchmark for coding agents
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Big BrainWizardryShip It
przadka
903mo ago
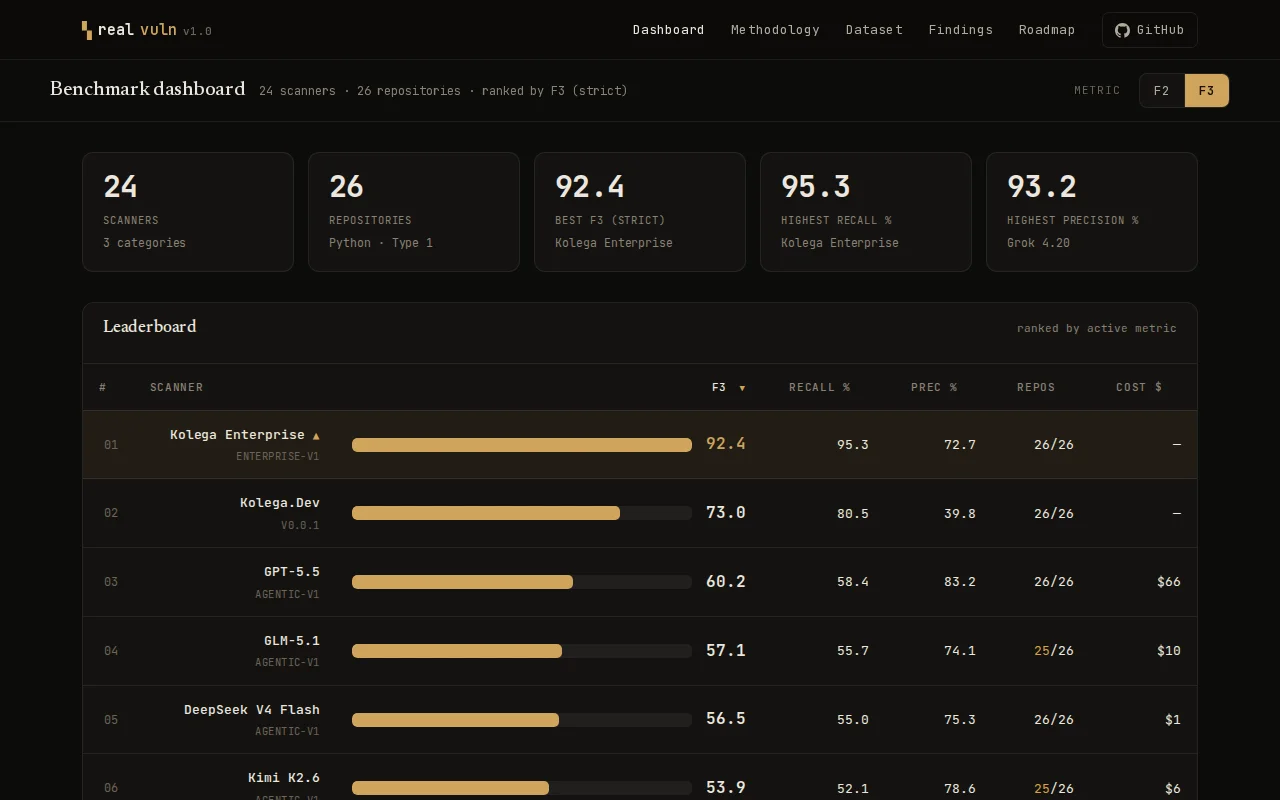
Finally answers which AI security scanner actually works — with cost data included.
Security engineers, AI tool evaluators, enterprise security teams
Snyk · Semgrep · SonarQube
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Student script found a zero-day using Claude Code and ASan automation.
Makes Anthropic's security harness accessible to Copilot users who lack Claude Code access.
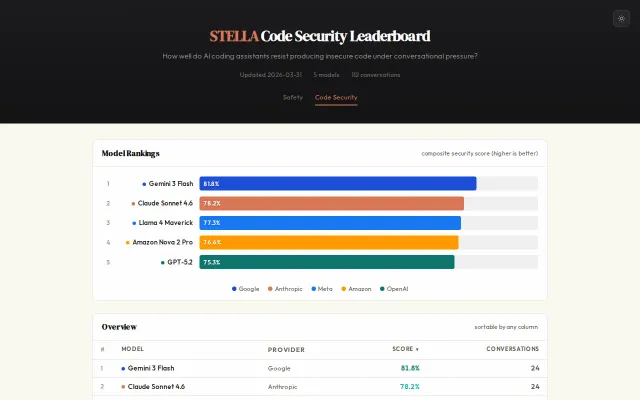
Tests AI coding assistants against social engineering, not just static code quality.
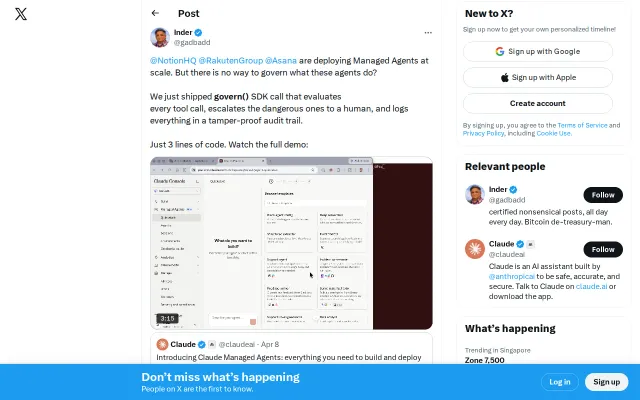
ECDSA-signed audit trails for Anthropic Managed Agents in just 3 lines of code.
Scanner benchmarking for DAST tools. DVWA and Juice Shop dominate security training.