AI/ML●●●Banger
Emergence World: World building as a way to evaluate LLMs
Runs GPT-5 and Grok in parallel societies to test emergent social structures.
Bold BetBig BrainWizardry
deepakakkil
301mo ago
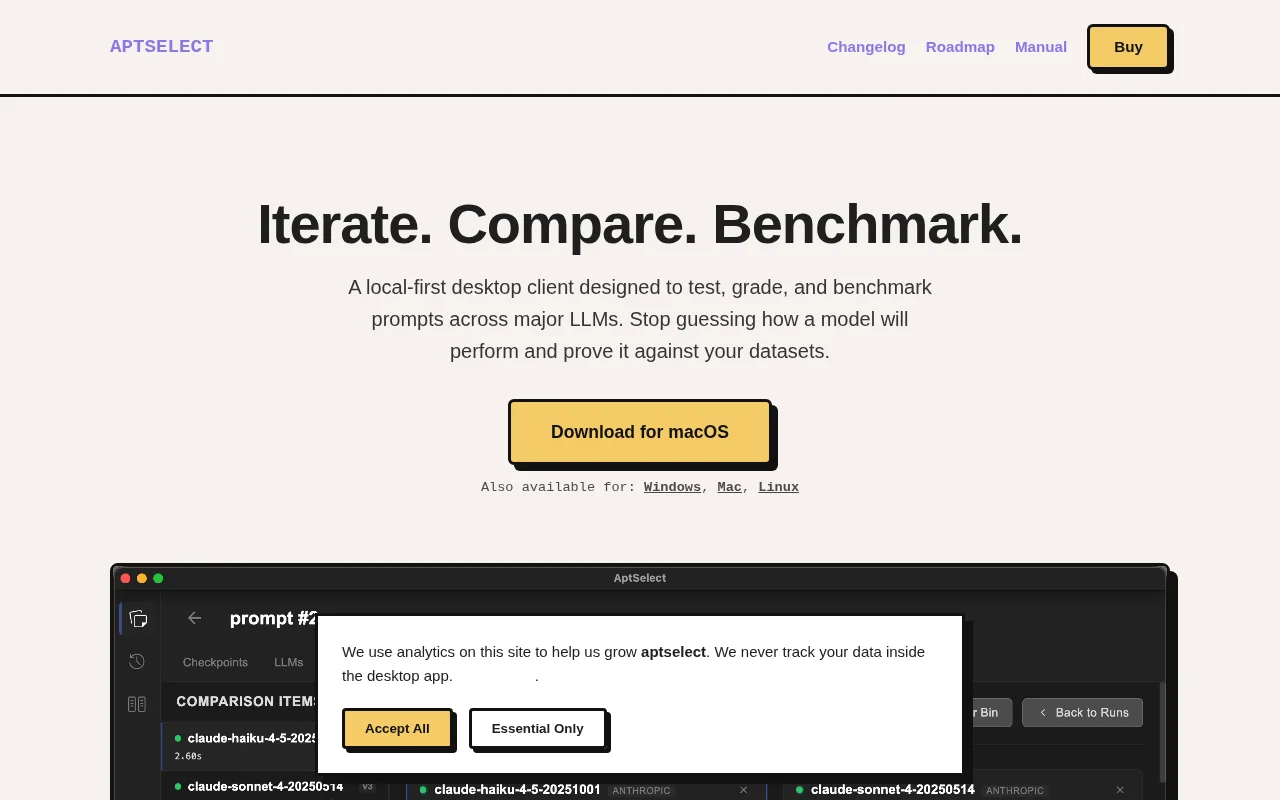
Parallel LLM testing across providers when LangSmith costs way more.
LLM developers and prompt engineers
LangSmith · Braintrust · Arize Phoenix
What it does:
Parallel Execution: Send a single prompt to OpenAI, Anthropic, Mistral, and Gemini simultaneously. Compare the outputs, latency, and exact token usage side-by-side.
Batch Evaluations: Upload a CSV dataset to run bulk tests across multiple models at once.
Manual Diagnostics: Grade outputs manually (Pass/Fail) and assign diagnostic tags (e.g., Hallucination, Format Error) to build a human-verified performance leaderboard.
Local-first: API keys encrypted with your OS keyring; history stored in a local SQLite DB; no telemetry.
I’m looking for technical feedback. What do you think current LLM testing/evaluation tools get most wrong?
Runs GPT-5 and Grok in parallel societies to test emergent social structures.
Phoenix LiveView embedding beats switching to LangSmith for Elixir teams.
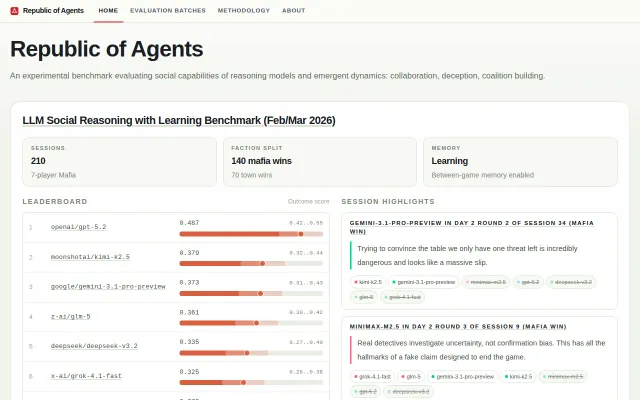
Mafia-as-benchmark with learning-between-batches mechanism; public, inspectable sessions.
Research framework with published paper, not a production red-teaming tool.
Fourteen parallel Claude agents grade your startup idea's evidence before you quit your job.
Qualitative eval workflow for PMs when LangSmith and Arize target ML engineers.