AI/ML●●Solid
AptSelect – A local LLM client for parallel testing and evaluation
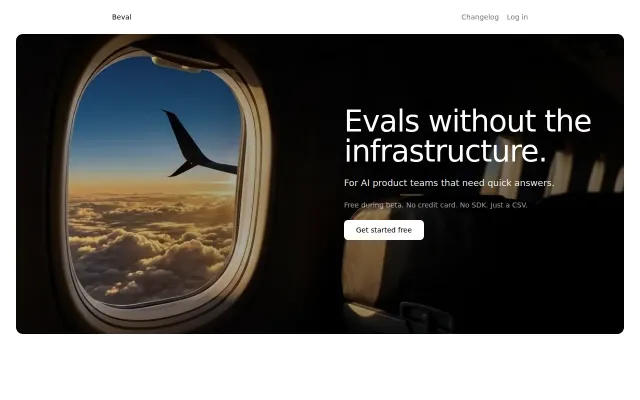
Parallel LLM testing across providers when LangSmith costs way more.
Solve My ProblemNiche Gem
dhavalt
301mo ago
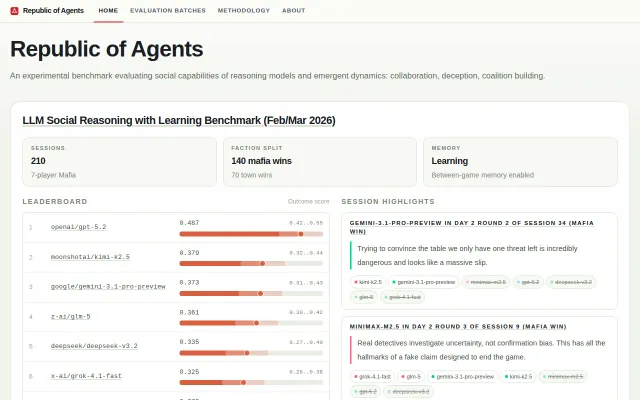
Runs GPT-5 and Grok in parallel societies to test emergent social structures.
AI researchers, LLM developers, Alignment researchers
Generative Agents · CivAI · AI Town
Parallel LLM testing across providers when LangSmith costs way more.
Catches LLMs cheating on evals with a 9-pattern catalog nobody else documents.
Fourteen parallel Claude agents grade your startup idea's evidence before you quit your job.
CSV-based evals beat LangSmith for quick PM checks without the infra headache.
Mafia-as-benchmark with learning-between-batches mechanism; public, inspectable sessions.
Streams evals from a tiny Python client into a shared dashboard and lets you run parameter sweeps and compare up to six configurations with radar/bar charts and scorecards — exactly the sort of tooling that stops results getting lost in notebooks. Useful, pragmatic product for teams who repeatedly evaluate models, but it's competing with general observability/experiment trackers (W&B, Neptune) and will need strong integrations and metric flexibility to stand out.