AI/ML●●●Banger
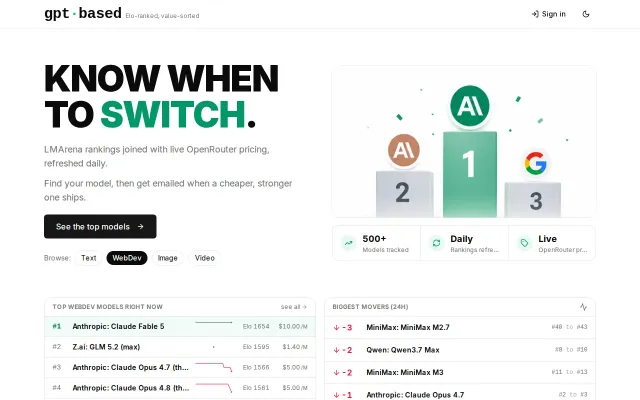
Auto LLM Ranker – Describe a task in English and get ranked models
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Big BrainDark HorseZero to One
gauravvij137
303mo ago
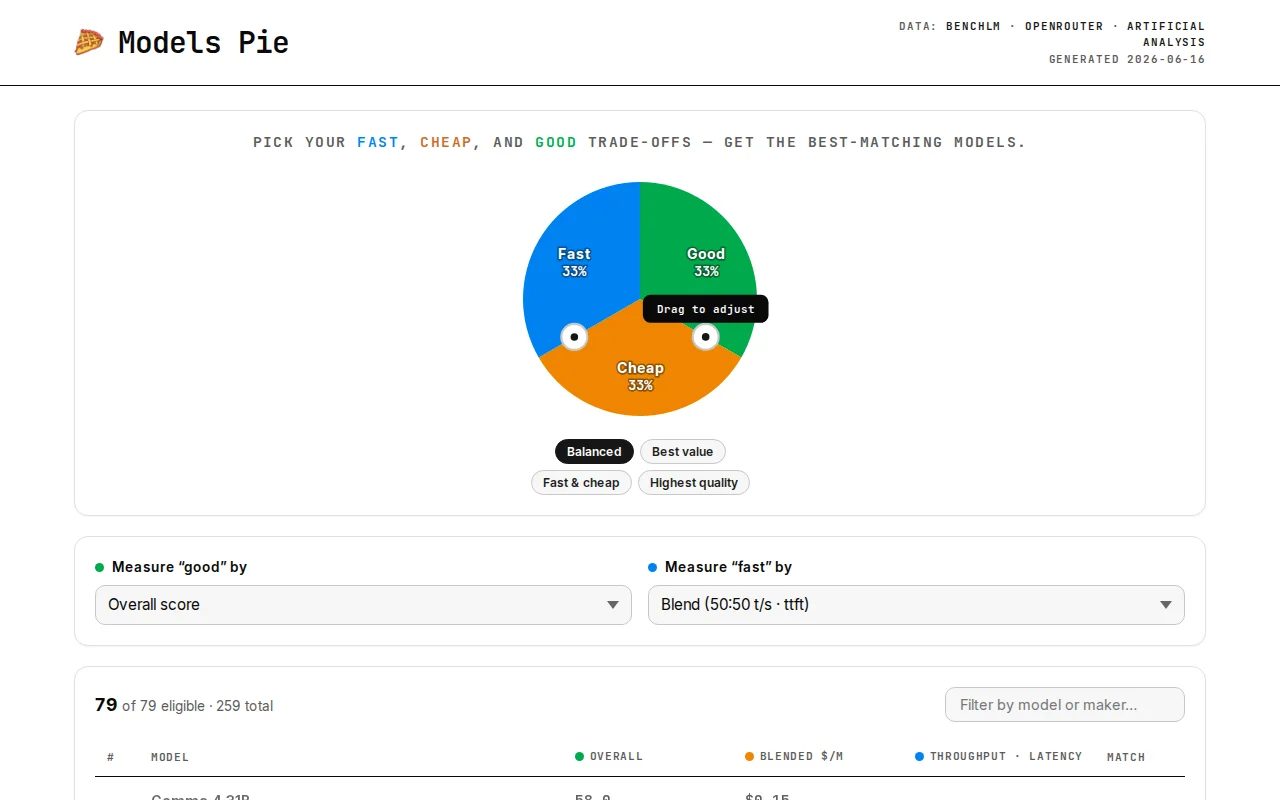
Pie chart trade-off weights beat static leaderboards for model selection.
Developers and teams selecting LLMs for specific use cases
LMSys Arena · Artificial Analysis · OpenRouter
You set your own trade-off priorities between fast, cheap, and good by dragging two handles around a pie chart to weight the three priorities, and a ranked table re-sorts live underneath. The data comes from BenchLM, OpenRouter and Artificial Analysis. Hope it's useful.
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
Agent loop proofreading evals where HELM and LMSys are too generic.
Pareto frontier optimization finds cheaper, stronger models when they ship.
Smart LLM routing cuts costs, but competing against established OpenRouter and vLLM ecosystems.
Live ML visualization of X's algorithm, but replicated behavior lacks ground truth.
Single HTML files become bidirectional UI—users click, LLMs call, both see results instantly.