Developer Tools●●Solid
Image Ranker – Open-Source Pairwise Ranking for Preference Learning
TrueSkill beats ELO by modeling uncertainty, cuts O(N²) comparisons to O(N) with sequential elimination.
Big BrainNiche Gem
quentinwach
202mo ago
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
AI engineers, developers selecting LLMs for production
LangSmith · Braintrust · Arize Phoenix
You describe a task in plain English. The tool generates a test suite for that specific task, discovers candidate models via OpenRouter, benchmarks them in parallel, and uses a Judge LLM to score every response across 5 dimensions: accuracy, hallucination, grounding, tool-calling, and clarity.
Output is a ranked top 3 with average latency per model and a task-specific system prompt optimized for the winner.
A few things I learned while building it:
- Score and latency rarely correlate. The best model for accuracy on coding tasks was almost never the fastest. This tradeoff is completely task-dependent and impossible to see from benchmarks that don't reflect your workload. - The Judge LLM approach is surprisingly consistent but introduces positional and familiarity bias. Using one model to score others isn't perfect, but it's far more reproducible than manual eval. Open to ideas on how to reduce judge bias without blowing up the cost. - Model discovery matters more than I expected. The top performers on generic benchmarks often weren't the top performers on narrow tasks.
Stack: Python, OpenRouter for model access, MIT licensed.
https://github.com/gauravvij/llm-evaluator
Happy to answer questions on the design decisions.
TrueSkill beats ELO by modeling uncertainty, cuts O(N²) comparisons to O(N) with sequential elimination.
Nine-chapter narrative arc beats fragmented blogs, openly licensed on GitHub.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.
One command finds and runs the best local LLM for your exact hardware specs.
TTFT-aware model fallback—avoids timeouts by hedging between Opus, Sonnet, Haiku automatically.
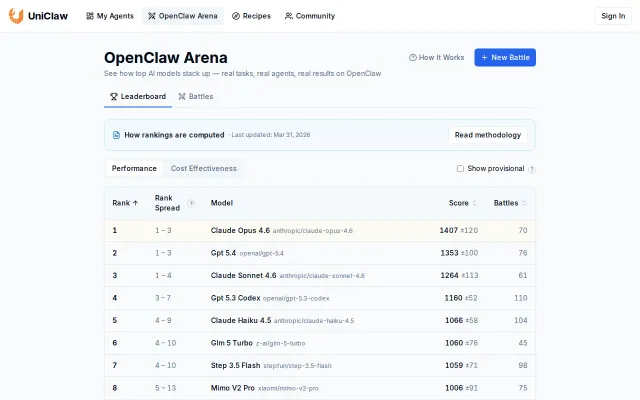
Finally benchmarks agents on real tasks instead of chat — separate cost and performance rankings.