AI/ML●●Solid
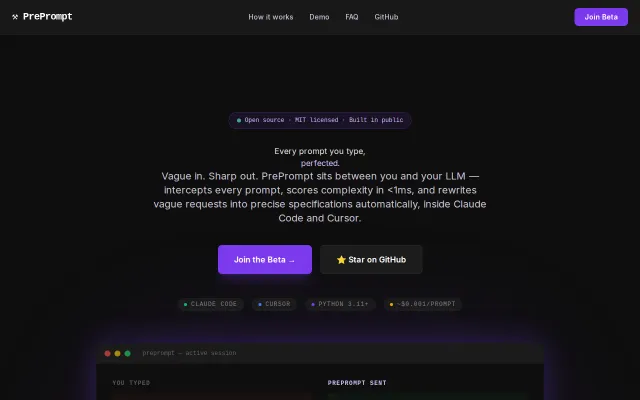
PrePrompt – rewrites vague prompts before they reach the LLM
Stack memory learns your preferences across sessions — FastAPI, typed code, SQLite.
SlickBig Brain
yashdeeptehlan
2391mo ago
Reverse Taboo gameplay doubles as LLM prompt comprehension benchmark dataset.
LLM researchers, prompt engineers, word game enthusiasts
Taboo · Heads Up · LLM benchmark suites
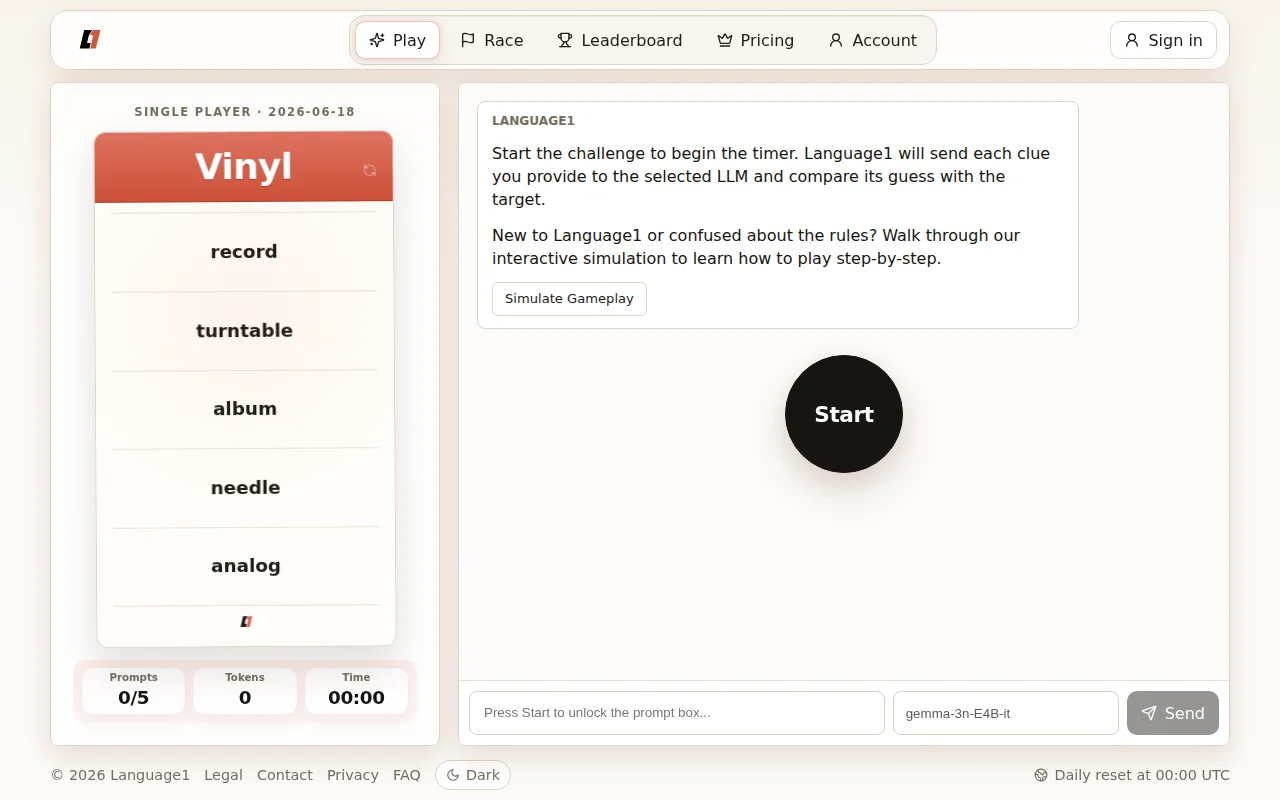
I built Language1 (https://language1.app), a word game where you play "reverse Taboo" against an LLM.
How it works: You are given a target word (e.g., "Apple") and a list of forbidden "taboo" words (e.g., "fruit", "red", "tree"). Your goal is to write a prompt that guides the LLM to output the exact target word, without using any of the forbidden words.
The Benchmark Goal: I am developing this project with the plan of using the gameplay data to build a benchmark dataset. The goal is to test and evaluate LLM capabilities when processing unclear prompts, metaphors, analogies, and vague explanations under semantic constraints.
Game Modes:
Single Player: Play through a pool of challenges to test your prompt precision. You compete against other players globally across attempts, solve time, and token consumption (measured via standard cl100k_base encoding). You can play instantly without registering, or sign in (one-click Google login) to submit scores to the leaderboards. Multiplayer Races: Real-time lobbies of up to 10 players racing through 3 rounds. Note: Since the game is new, public lobbies might be empty at first, but you can create private lobbies to play with friends. Available Models:
Anonymous users play with the default Gemma 3 Instruct model. Free registered users can choose between multiple models to test and compare reasoning styles, including Llama 3 8B, Liquid LFM 24B, Amazon Nova Micro, and Ministral 8B.
The Tech & Guardrails: The app is built with a React frontend and a Node.js/AWS Lambda backend. To keep things fair, we built a validation guard that parses input clues to block easy bypasses like letter-spacing (e.g., "A-P-P-L-E"), translations, cyphers, and base64. You have to rely purely on semantic reasoning to guide the model.
The game is completely free, has no ads, and is playable instantly in the browser.
I'd love to hear your thoughts on the gameplay and see what creative semantic tricks you use to guide the LLM!
Stack memory learns your preferences across sessions — FastAPI, typed code, SQLite.
Sequential-dispatch methodology corrects 20x overestimation in prior WebGPU benchmarks.
Home rig for attribute-weighted benchmarking lacks the polish of established eval frameworks.
LLM-voted tool benchmarks when StackShare and G2 already exist.
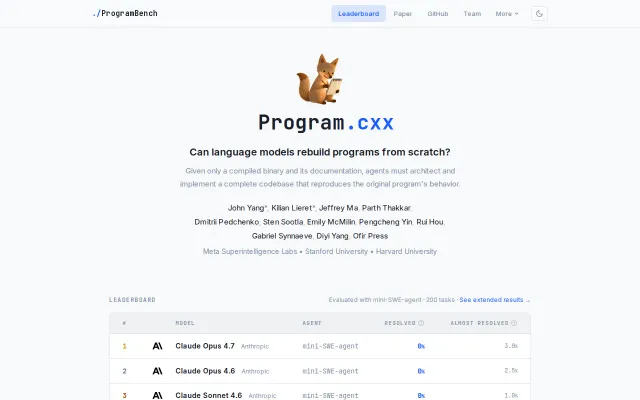
Agents fail completely at rebuilding binaries from scratch without source code.
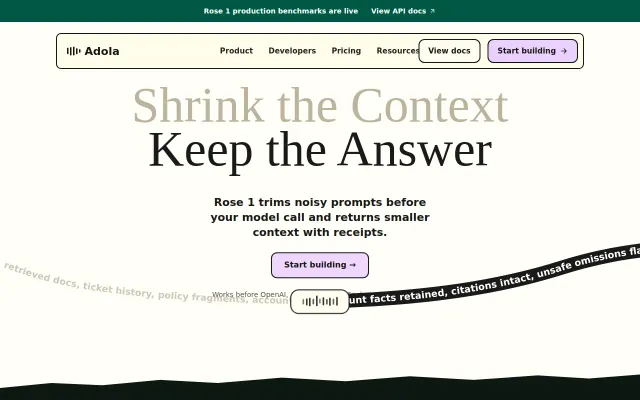
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.