AI/ML●●Solid

HighSNR – Cut length and noise from your LLM context
Beats full-context GPT-4o at 80% token budget with zero AI overhead.
Big BrainSolve My Problem
gskm
654mo ago
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
AI engineers building RAG systems and support copilots
Jina AI Reader · Firecrawl · LLMLingua
Beats full-context GPT-4o at 80% token budget with zero AI overhead.
Entropy-based context compression beats naive token stuffing, but the category is crowded.
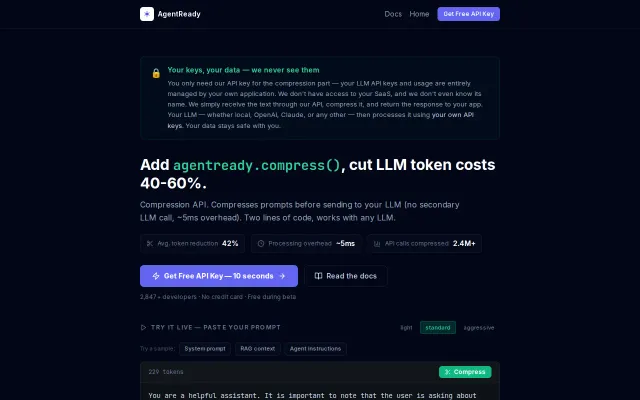
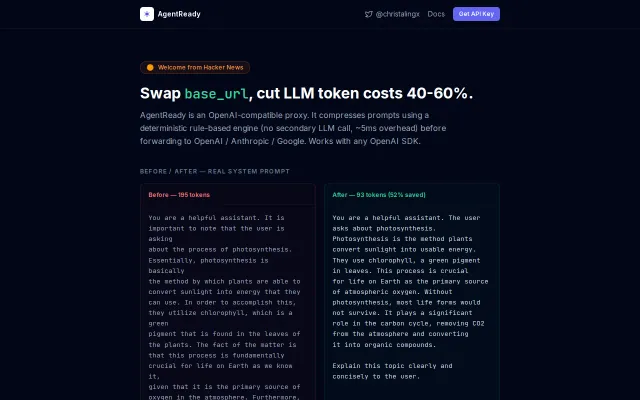
Prompt compression cuts token costs 40-60%, but prompt optimization isn't new.
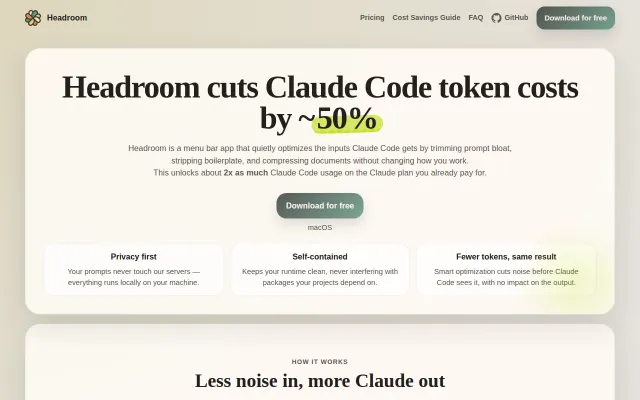
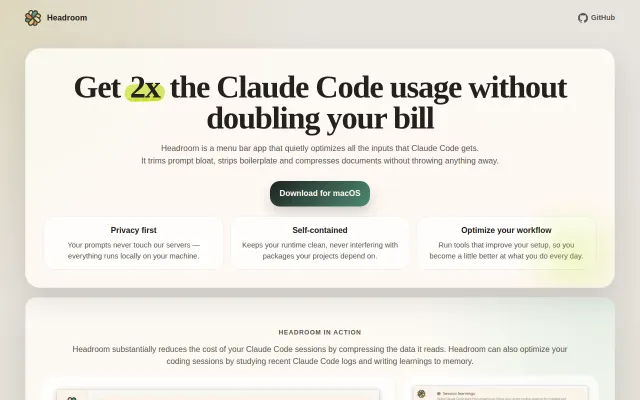
60 DAUs saved 10.5B tokens — real savings for Claude Code power users.
Mac app wrapper around Headroom compression for Claude Code.
Drop-in proxy that cuts GPT token costs 40-60% without changing app code.