AI/ML●●Solid
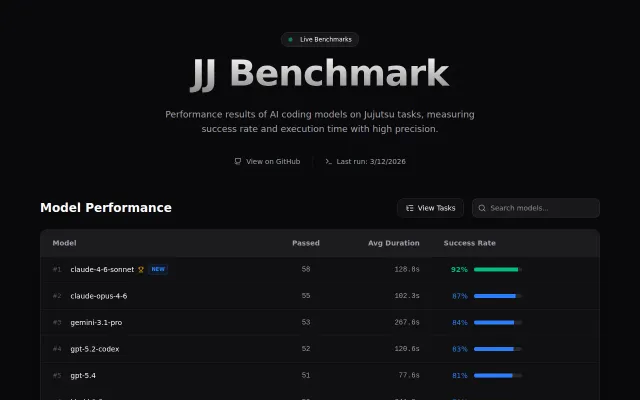
jj-benchmark – Evaluating AI agents on Jujutsu version control
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.
Niche GemBig Brain
wsxiaoys
523mo ago
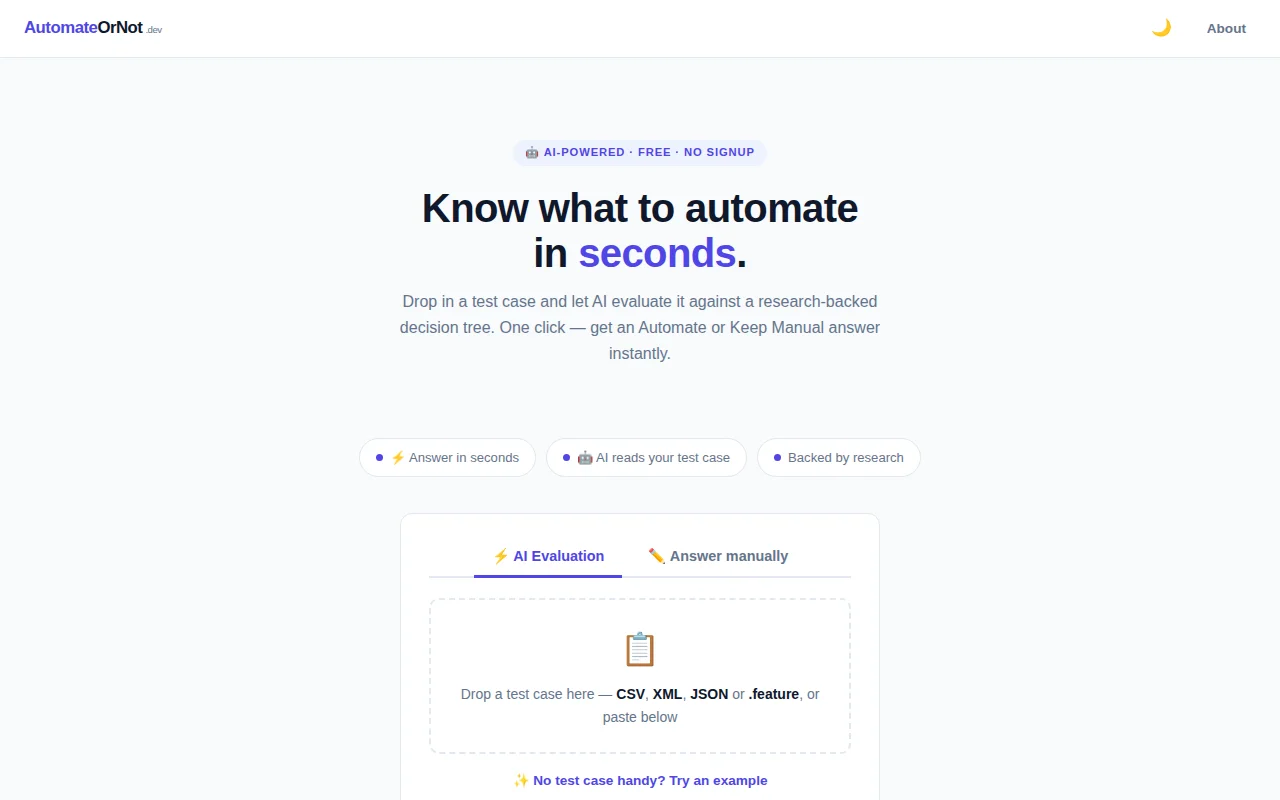
Research-backed decision tree from a Master's thesis, but it's still an AI wrapper on existing frameworks.
QA engineers, test automation leads, development teams
TestRail · qTest · various test management tools
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.
Replaces manual Playwright scripting, but Claude-generated tests and GitHub Copilot already cover this.
AI finds 250 bugs in LiteLLM, LobeChat, but no demo or accessible entry point.
Agent testing platform, but screenshot only shows login page—no actual product demo or proof.
Factorization machines select optimal LLM sub-pools for each classification task.
Yet another versioning tool with no clear differentiation from semantic-release.