AI/ML●●●●Gem
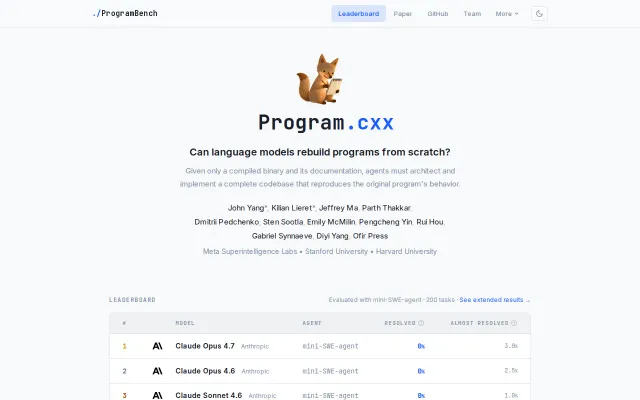
New Benchmark from SWE-bench team is 0% solved
Agents fail completely at rebuilding binaries from scratch without source code.
Big BrainBold BetZero to One
lieret
2431mo ago
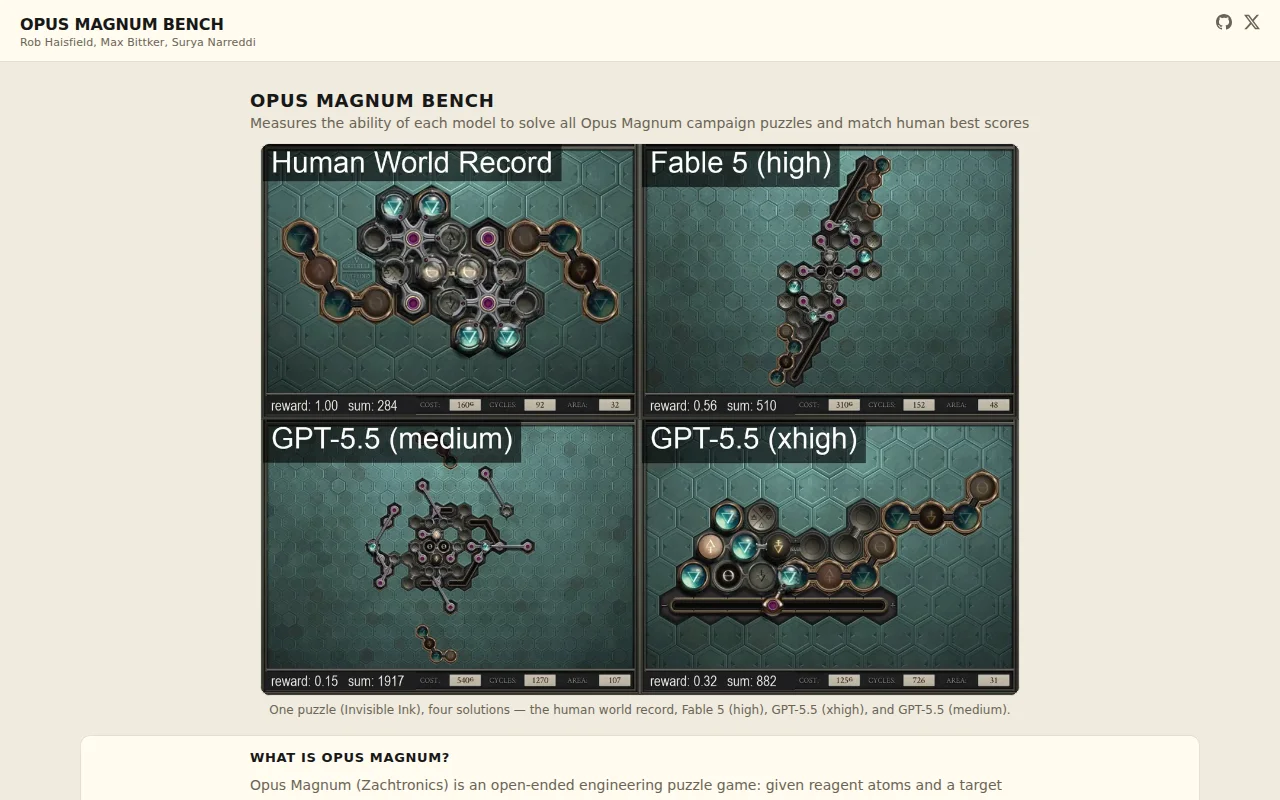
Game-based AI benchmark measuring spatial reasoning against human speedrun records.
AI researchers, ML engineers evaluating spatial reasoning capabilities
HumanEval · BIG-bench · ArcAGI
Agents fail completely at rebuilding binaries from scratch without source code.
Article about Claude Opus 4.7 with no actual tool or code.
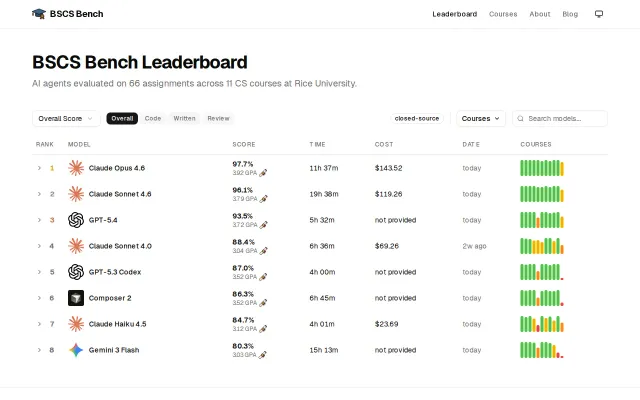
Real CS coursework beats synthetic coding benchmarks for model evaluation.
Unsupervised bug benchmark using agents as both attackers and defenders—novel scoring methodology.
Bit-exact rotations via surd field extension, but is the problem worth solving?
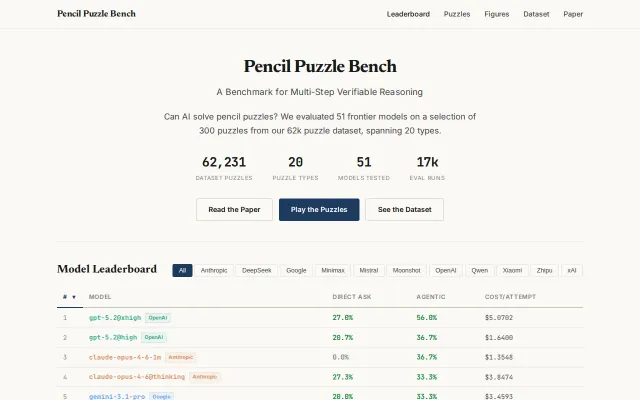
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.