Developer Tools●●Solid
Let AI agents debug your Valkey/Redis
MCP server for Valkey monitoring when generic database MCP tools already exist.
Niche Gem
kaliades
203mo ago
Real-time monitoring, slowlog analysis, and audit trails for Valkey and Redis
Valkey-native agent cache runs on vanilla Valkey with no modules required.
AI engineers building agent systems with Valkey/Redis
LangChain Memory · LlamaIndex · Mem0
Why we made it: BetterDB originally started as a monitoring and observability platform for Valkey, Redis and any RESP compatible db. This is still the core of the product, but in the process of building this, we kept seeing that one of the fastest-growing uses of Valkey was AI - vector store and cache behind agents and RAG. So about a month and half ago we published MIT semantic and agent cache libraries for that, with the agent cache library not even requiring any modules and being able to run on vanilla Valkey. Today we are extending this to agent memory. Because we started with observability, it also runs everywhere - every cache, memory and retrieval emits OTel and Prometheus, plus it integrates well with our own monitoring and mcp server, exposing it to the agent.
What we actually shipped: - agent memory: short-term tiers (session/LLM/tool, exact-match) plus a semantic long-term layer - semantic caching over valkey-search, with per-category thresholds and confidence bands - typed retrieval over valkey-search - a self-tuning loop and OTel/Prometheus observability (more below)
What's not done yet: a Helm chart for one-command self-hosting, and a detailed benchmark writeup. Both next week.
Self-tuning cache. The cache logs similarity scores, and a separate service reads the distribution and proposes threshold/TTL changes (with reasoning, weighted by cost). A human approves the change, and the running cache picks it up in under a second with no restart. An agent can read the live cache state and propose changes over MCP. I haven't found another cache library that closes this loop; most use a static, hand-tuned threshold, which is the documented failure mode for semantic caches. Observability at the operation level. OTel spans and Prometheus metrics on each cache/memory/retrieval operation, not just request-level LLM tracing. So you can actually see per-lookup similarity distributions and whether your threshold is wrong, rather than guessing.
On benchmarks, the number isn't a flex: I ran LongMemEval on the memory layer. In the process of building our harness I found multiple things surpressing the scores. Even tweaking the prompt to the reader (the reader was told to answer only from literal excerpts so it abstained on whole question types), on a matched gpt-4o config the improvement was over 5 points. We'll be actively working on QA next week. Re-run everything and then publish a comprehensive write up. Retrieval recall is near-perfect at 98.4%, so the gap is reader/reasoning-side, not retrieval. The best part is ofc latency as Valkey's performance is great.
What I'd genuinely like feedback on: does the Valkey-native bet make sense to you, or would you rather a context layer be storage-agnostic? And for those running agents in prod, would you trust automated self tuning recommendations, or prefer to keep it manual? Is cost or latency a bigger issue to be solved?
We have a public unscripted demo at chat.betterdb.com btw, if anyone wants to see these libraries in action.
MCP server for Valkey monitoring when generic database MCP tools already exist.
Multi-tier cache for AI agents with built-in OpenTelemetry and Prometheus metrics.
Slowlog persistence solves real Redis pain—captures every entry before rotation, no VPC peering required.
Persists Redis/Valkey's ephemeral observability data with rigorous interleaved benchmarking proving sub-1% overhead.
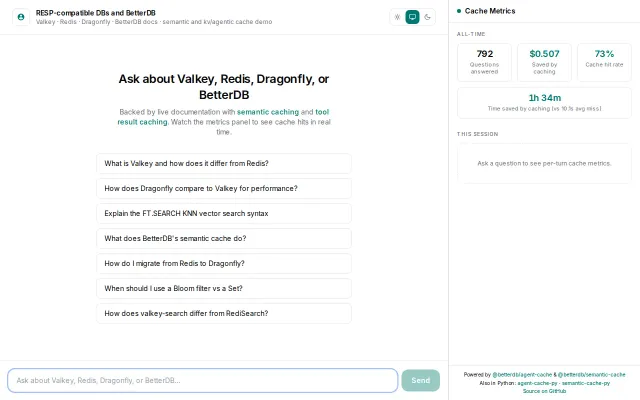
Two-tier caching saves real money, shown live on the dashboard.
Auto-ingests wikis to fix agent SQL accuracy when Claude Code hallucinates metrics.