Productivity●●Solid
A free browser extension to extract tables
OCR-based extraction handles images and PDFs where standard DOM scrapers fail.
Solve My ProblemSlick
viniciuscsr
102mo ago
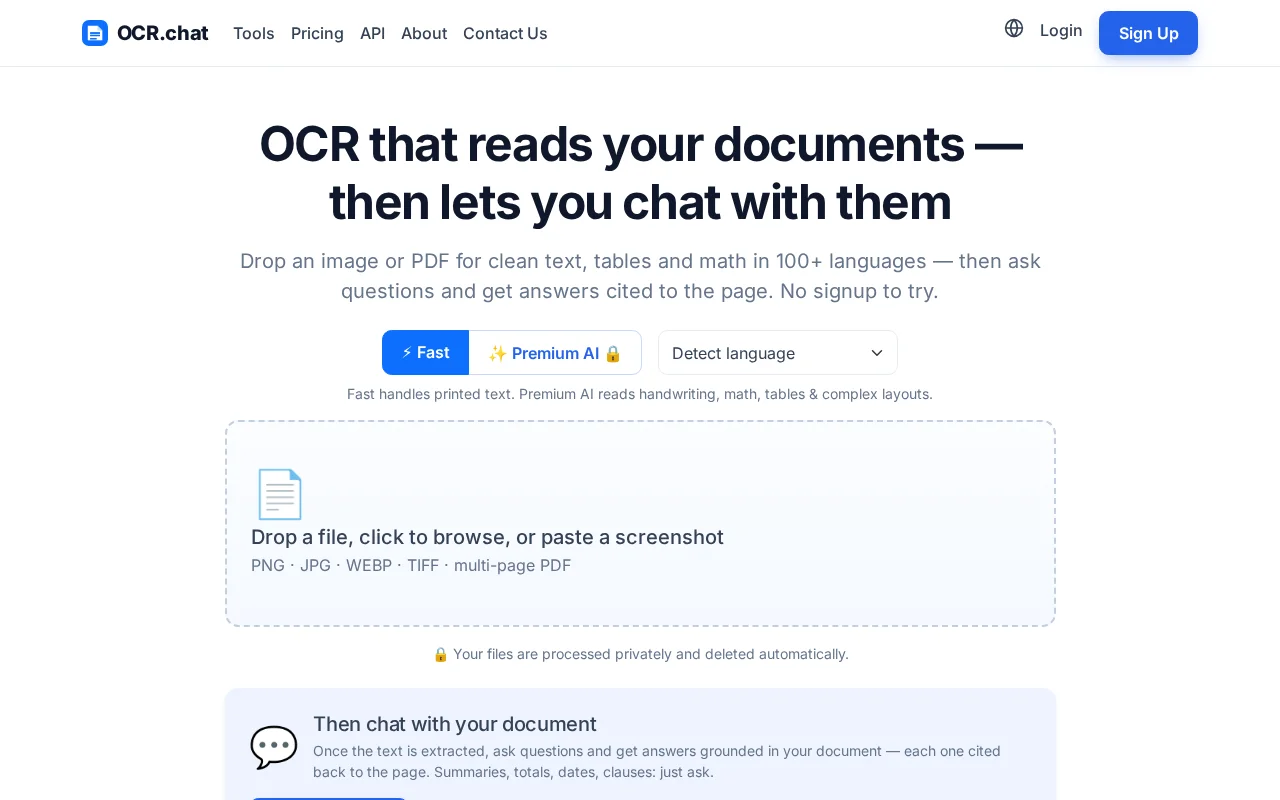
OCR plus RAG in one flow handles scanned docs that break standard PDF chat tools.
Researchers and professionals handling scanned documents
ChatPDF · Adobe Acrobat AI · Humata
OCR-based extraction handles images and PDFs where standard DOM scrapers fail.
Typesense + Tika + OCR for semantic local file search; read-only, privacy-first, no servers.
ProofPudding returns extraction results with explicit links back to the exact page and source text, supports native and scanned PDFs plus DOCX/images, and ships Python/TypeScript SDKs — handy for agents that need auditable facts. It’s a pragmatic product (per-extraction pricing and confidence scores are nice), but the market is crowded; I want clarity on underlying models, real-world accuracy numbers, and how it compares to Document AI/Textract in edge cases.
94.5% accuracy, self-hostable, open source—beats Textract on cost and accuracy.
Edit scanned PDFs visually without OCR, like moving layers in Photoshop.
CPU-only OCR with clipboard in/out beats Tesseract for modern screenshots.