AI/ML●●●Banger
OS Megakernel that match M5 Max Tok/w at 2x the Throughput on RTX 3090
Single CUDA dispatch beats M5 Max efficiency on a 2020 GPU — llama.cpp extracts 40% of available performance.
WizardryBig Brain
GreenGames
612mo ago
Another 4B Qwen fine-tune without benchmarks showing it beats existing models.
Developers running local LLMs
Qwen3-4B-Instruct · TinyLlama · Phi-3-mini
Single CUDA dispatch beats M5 Max efficiency on a 2020 GPU — llama.cpp extracts 40% of available performance.
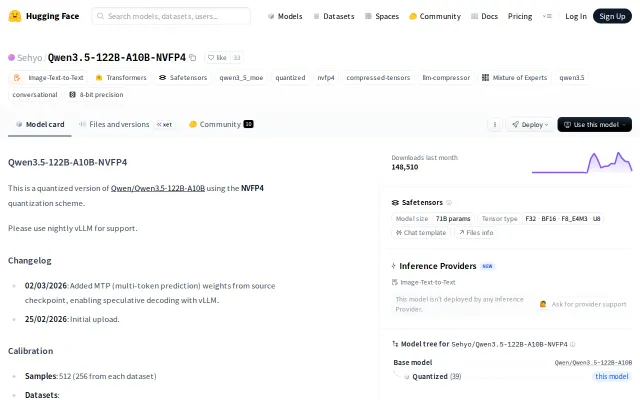
Bypasses NVIDIA's artificial FP4 lock—122B MoE on single desktop GPU at 31 tok/s.
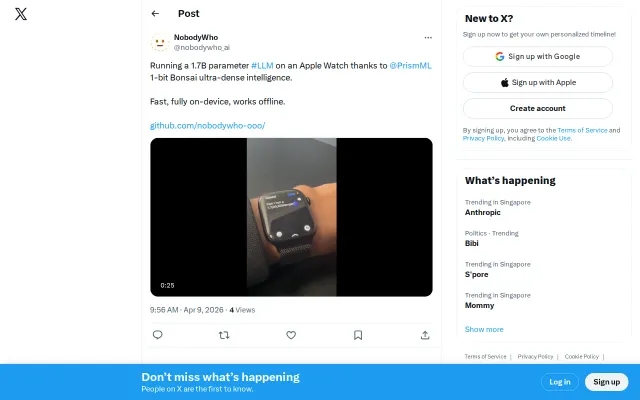
Runs a 1.7B LLM offline on Apple Watch using 1-bit quantization.
1.58-bit quantization + layer streaming shrinks 144GB models to 36GB, runs on Mac Mini.
24M params in 15MB using GPTQ-lite and Muon optimizer for OpenAI's Parameter Golf challenge.
Detects hallucinations mid-generation via hidden state geometry, not output analysis.