AI/ML●●●Banger

We've built a standalone Apple Watch app running LLMs offline, locally
First standalone Apple Watch LLM app running 700M-1.7B models completely offline.
WizardryZero to OneDark Horse
pielouNW
301mo ago
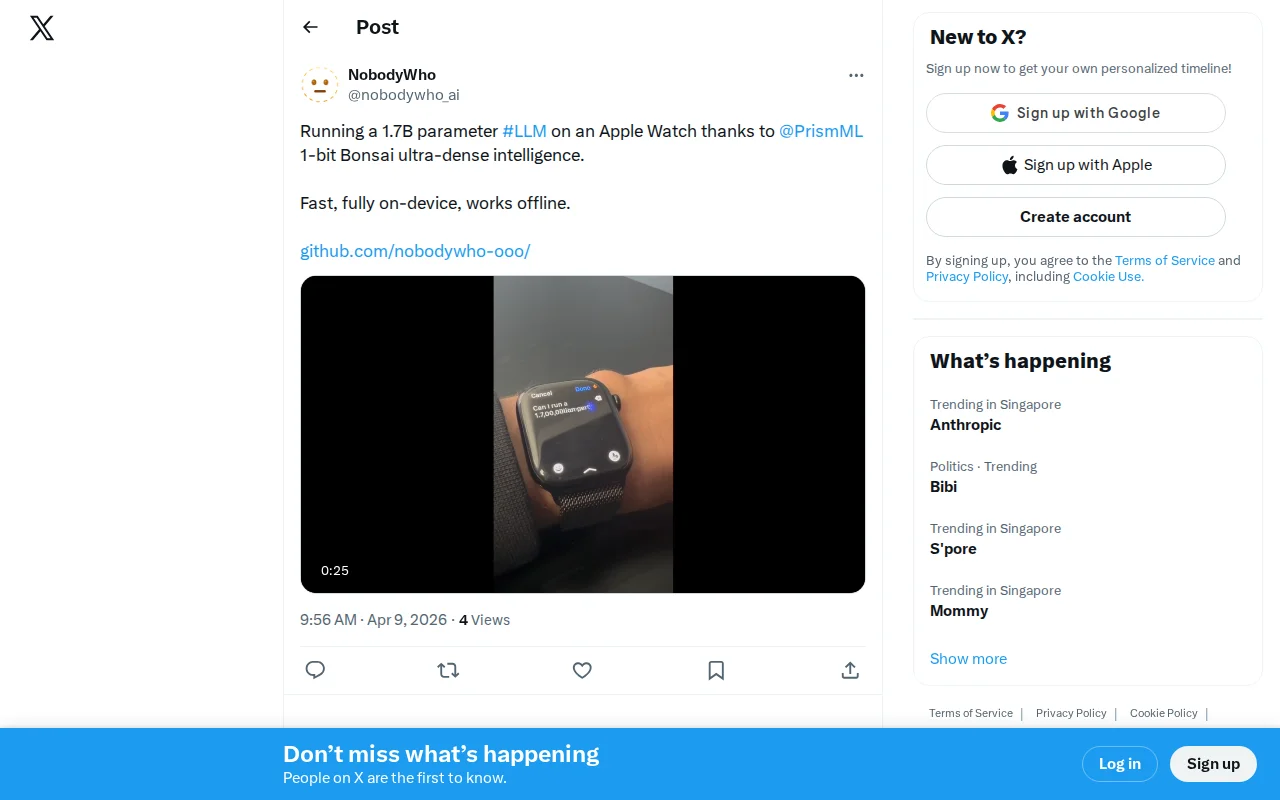
Runs a 1.7B LLM offline on Apple Watch using 1-bit quantization.
Edge AI developers, Apple Watch enthusiasts
MLC Chat · Llama.cpp · Off Grid
First standalone Apple Watch LLM app running 700M-1.7B models completely offline.
1.58-bit quantization + layer streaming shrinks 144GB models to 36GB, runs on Mac Mini.
24M params in 15MB using GPTQ-lite and Muon optimizer for OpenAI's Parameter Golf challenge.
Ternary quantization and layer streaming for 140B models on Mac Mini, but claims lack real-world validation.
LLM inference inside Scratch at 1 token per 10 seconds — absurd, intentional, and it works.
Ranks models by actual benchmark scores instead of just fitting the biggest model in VRAM.