AI/ML●●Solid
Agent Action Guard – AI agent action safety
HarmActionsEval benchmark proves GPT and Claude fail at blocking harmful tool use.
Solve My ProblemNiche Gem
praneeth-v
203mo ago
99% prefill compute reuse enables sub-30ms agent behavior classification.
Teams running production AI agents at scale
LangSmith · Arize Phoenix · Helicone
How it works:
We use a modern LLM with hybrid attention and remove the decode step. We built an inference engine that lets prefill compute be 99% reused from reflex to reflex, similar in spirit to older 2019-era BERT/HYDRA + older multiple-head techniques.
We took the same high-level idea and did the hard work to make it work with a modern architecture and attention. On it, we can run inference in under 30ms and serve the full request in under 90ms. If you run 4 reflexes or 100, the extra overhead is less than 2ms.
Why does optimizing this matter?
If you’re even a medium-sized startup, you’re dealing with tens of thousands of agent runs and millions of turns. If you want to track things like user frustration rates over time, frontier LLM-as-judge does not scale.
I built a similar stack at Tesla. When ML engineers needed to sample data across petabytes for signals like `is_camera_obfuscated=true`, along with 200 other things, you need to 1) spin them up quickly 2) run at scale efficiently
What it is not:
A dashboard. In my experience, 99% of dashboards go unused. This is purely API-based and made for devs who want to track agent behavior themselves and trigger their own alerts and build on it.
You can vibetrain a custom reflex in our dashboard, and then let it self improve in production: https://www.morphllm.com/dashboard/reflex
Docs: https://docs.morphllm.com/sdk/components/reflexes/index
I’d love feedback from people running agents in prod: what sorts of things do you wish you could track over time across 100% of turns?
TLDR: semantic signals from agent traces, super fast, cheap via API
HarmActionsEval benchmark proves GPT and Claude fail at blocking harmful tool use.
Lyapunov stability theory catches token spirals before your budget explodes.
Lyapunov stability theory applied to LLM agents — classifies failures with zero extra API calls.
Outperforms existing open-source injection detectors on ProtectAI and Qualifire benchmarks.
LLM classifies YouTube content and kills power via WebOS if kids don't switch.
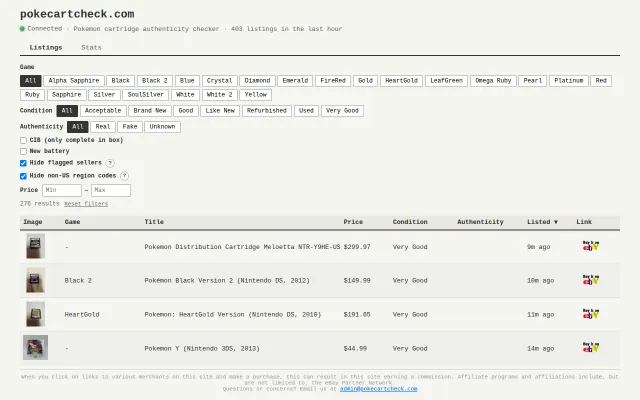
Runs eBay listings through a fake-cartridge classifier before you click the link.