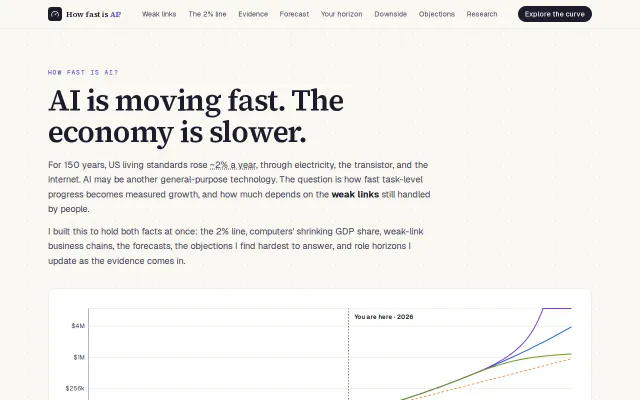
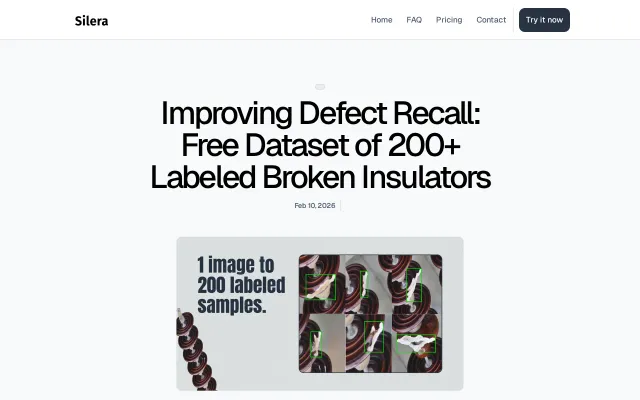
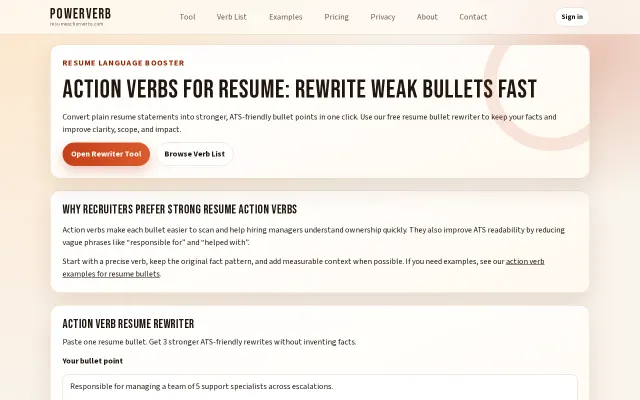
Data●●Solid
MedSynth – Multi-lingual synthetic healthcare data with OCR artifacts
This isn't another clean, English-only faker — it intentionally models script-specific OCR errors (Hebrew/Arabic/Latin confusions), per-hospital schema variance, and country-specific ID formats so models see the sort of mess real systems do. Output is NDJSON and usable from the CLI, which makes it straightforward to plug into pipelines, but the repo looks very new and documentation/examples are thin — promising concept, you’ll still need to tinker to use it at scale.
Niche GemWizardry
Alechko
114mo ago