AI/ML●●●Banger
Run 500B+ Parameter LLMs Locally on a Mac Mini
1.58-bit quantization + layer streaming shrinks 144GB models to 36GB, runs on Mac Mini.
WizardryZero to OneBig Brain
fatihturker
17103mo ago
LLM inference inside Scratch at 1 token per 10 seconds — absurd, intentional, and it works.
Scratch/TurboWarp users, demoscene programmers, constraint-coding enthusiasts
llama2.c · TurboWarp (VM fork) · Constraint-coding demoscene projects
I started this as an experiment in how far Scratch's VM could be pushed, and because the idea of running an LLM inside Scratch felt absurd and fun. The main challenges were fitting quantized weights into list memory, working around JS call stack limits, and patching llvm2scratch to support additional IR patterns emitted by clang -O2.
Generates ~1 token every 10 seconds.
Live demo: https://scratch.mit.edu/projects/1277883263
1.58-bit quantization + layer streaming shrinks 144GB models to 36GB, runs on Mac Mini.
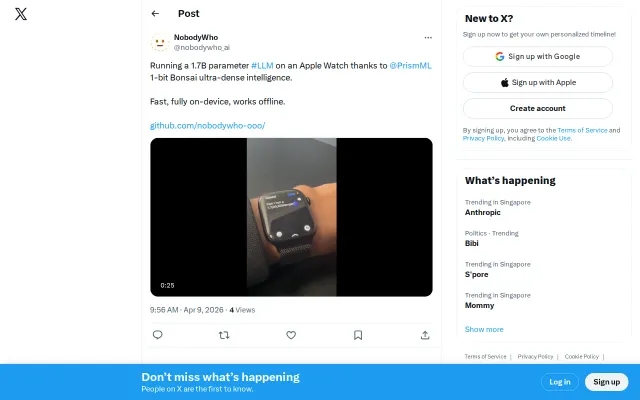
Runs a 1.7B LLM offline on Apple Watch using 1-bit quantization.
Hardware-backed private inference, but requires trust in Onera's server infrastructure anyway.
E8 lattice codebooks beat GPTQ at 2-4 bpw with fused CUDA kernel skipping weight materialization.
24M params in 15MB using GPTQ-lite and Muon optimizer for OpenAI's Parameter Golf challenge.
In-process LLM inference in PHP beats the usual Python sidecar pattern.