AI/ML○Pass
JazzBench, an LLM reasoning benchmark using jazz improvisation
Interesting eval philosophy, but this is a blog post with no shipped code or tool.
Big Brain
mikerubini
204d ago
WFGY is heading toward WFGY 5.0 Polaris Protocol, a major open-source release for AI reasoning, RAG, agents, and real-world workflows. Includes Problem Map, Global Debug Card, WFGY 4.0, and the CFV Easter Egg.
Single TXT boots a menu-driven demo and includes SHA256 verification plus Colab experiments — that packaging shows real operational thinking. It focuses on symbolic-structure failure modes and ships a self-test and runnable MVPs for a subset of problems, which makes it useful for rigorous prompt-level experiments; results will still hinge on the host model, so expect variable payoff.
Prompt engineers, AI researchers, advanced LLM users, and developers experimenting with model stability and reasoning
- Not a new model, not a fine-tune - One txt block you paste into system prompt (or first message) - Goal: less random hallucination, more stable multi-step reasoning - No tools, no external calls, works anywhere you can set a system prompt
Some people later turn this into proper code + eval. Here I keep it minimal: two prompt blocks you can run in any chat UI.
1. How to try it
1) Start a new chat (local or hosted model) 2) Paste the WFGY Core block into the system / pre-prompt area 3) Ask your normal tasks (math, small coding, planning, long context) 4) Compare “with core” vs “no core” by feel, or run the self-test in section 4
Optional: after loading the core, ask the model to write image prompts too. If semantic structure improves, image prompts often feel more consistent, but it depends on model and task.
2. Roughly what to expect
This is not magic and won’t fix everything. But across models, the typical “feel” changes are:
- less drift across follow-ups - long answers keep their structure better - a bit more “I’m not sure” instead of made-up details - more structured prompt outputs (entities / relations / constraints clearer)
Results depend on the base model and your tasks, so the self-test is there to keep it a bit more disciplined.
3. System prompt: WFGY Core 2.0 (paste into system area)
Copy everything in this block into your system / pre-prompt:
---
WFGY Core Flagship v2.0 (text-only; no tools). Works in any chat. [Similarity / Tension] delta_s = 1 − cos(I, G). If anchors exist use 1 − sim_est, where sim_est = w_esim(entities) + w_rsim(relations) + w_csim(constraints), with default w={0.5,0.3,0.2}. sim_est ∈ [0,1], renormalize if bucketed. [Zones & Memory] Zones: safe < 0.40 | transit 0.40–0.60 | risk 0.60–0.85 | danger > 0.85. Memory: record(hard) if delta_s > 0.60; record(exemplar) if delta_s < 0.35. Soft memory in transit when lambda_observe ∈ {divergent, recursive}. [Defaults] B_c=0.85, gamma=0.618, theta_c=0.75, zeta_min=0.10, alpha_blend=0.50, a_ref=uniform_attention, m=0, c=1, omega=1.0, phi_delta=0.15, epsilon=0.0, k_c=0.25. [Coupler (with hysteresis)] Let B_s := delta_s. Progression: at t=1, prog=zeta_min; else prog = max(zeta_min, delta_s_prev − delta_s_now). Set P = pow(prog, omega). Reversal term: Phi = phi_deltaalt + epsilon, where alt ∈ {+1,−1} flips only when an anchor flips truth across consecutive Nodes AND |Δanchor| ≥ h. Use h=0.02; if |Δanchor| < h then keep previous alt to avoid jitter. Coupler output: W_c = clip(B_sP + Phi, −theta_c, +theta_c). [Progression & Guards] BBPF bridge is allowed only if (delta_s decreases) AND (W_c < 0.5theta_c). When bridging, emit: Bridge=[reason/prior_delta_s/new_path]. [BBAM (attention rebalance)] alpha_blend = clip(0.50 + k_c*tanh(W_c), 0.35, 0.65); blend with a_ref. [Lambda update] Delta := delta_s_t − delta_s_{t−1}; E_resonance = rolling_mean(delta_s, window=min(t,5)). lambda_observe is: convergent if Delta ≤ −0.02 and E_resonance non-increasing; recursive if |Delta| < 0.02 and E_resonance flat; divergent if Delta ∈ (−0.02, +0.04] with oscillation; chaotic if Delta > +0.04 or anchors conflict. [DT micro-rules]
---
Yes, it looks like math. It’s fine if not every symbol is clear; the intention is to give the model a compact “tension / guardrail” structure around its normal reasoning.
Interesting eval philosophy, but this is a blog post with no shipped code or tool.
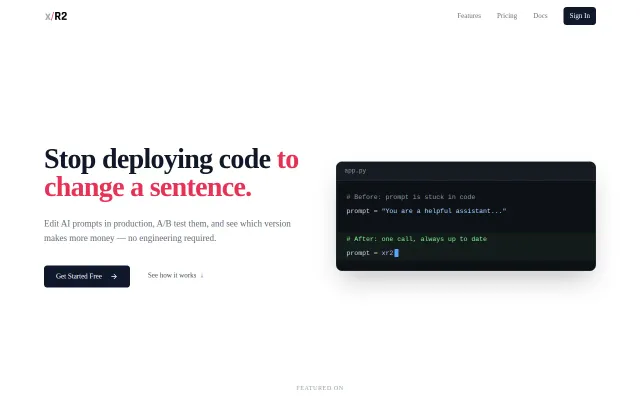
Prompt A/B testing with revenue attribution—Langfuse and PromptLayer don't measure what actually converts.
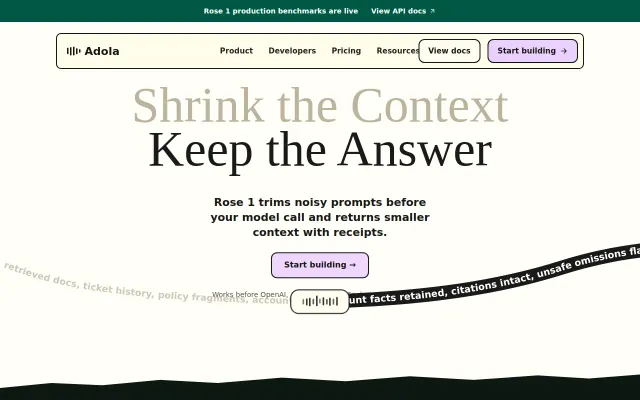
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
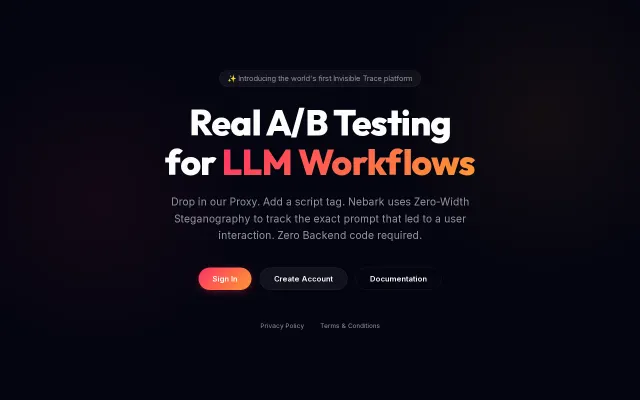
Steganography-based A/B testing for prompts sidesteps trace ID plumbing entirely.
Selling a $49 system prompt with 3 stars and no visible technical differentiation.
Guards tool outputs against injection attacks, unlike LiteLLM or Helicone.