Developer Tools●●●Banger
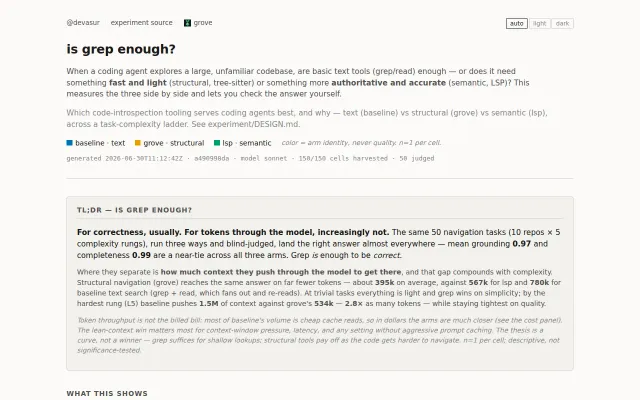
Tilth v0.5.0 –> ~40% cheaper AI code navigation (160 runs, 3 models)
44% cheaper Claude code navigation via tree-sitter definitions + call resolution.
WizardryBig BrainSolve My Problem
jahala
424mo ago
Smart(er) code reading for humans and AI agents. Reduces cost per correct answer by ~40% on average. Install: cargo install tilth -or- npx tilth
Instruction tuning on tool descriptions cut Sonnet costs 29% without code changes.
AI engineers, backend developers, devops teams using Claude for code analysis
Sourcegraph Cody · Continue.dev · Cursor
--
v0.4.0 added search ranking, sibling surfacing, transitive callees, cognitive load stripping, smart truncation, and bloom filters. Got -17% on Sonnet, -20% on Opus.
v0.4.1 was pure instruction tuning — zero code changes that alone jumped Sonnet adoption from 89% to 98% and $ cost/correct answer from -17% to -29%.
The instruction tuning result surprised me. The model already knew tilth tools existed — it just wasn’t choosing them consistently. Making the replacement relationship explicit in the tool description was worth more than all the search ranking work in v0.4.0.
Haiku remains the outlier — only 42% tilth adoption despite instruction tuning.
--
https://github.com/jahala/tilth/
Full results: https://github.com/jahala/tilth/blob/main/benchmark/README.m...
-- PS: I dont have the budget to run the benchmark a lot (especially with Opus), so if any token whales has capacity to run some benchmarks, please feel free to PR results.
44% cheaper Claude code navigation via tree-sitter definitions + call resolution.
Tree-sitter MCP cuts Claude code task costs 17–82% while improving accuracy.
Grep wins on correctness, but tree-sitter cuts tokens by 50% on hard tasks.
Clever pinch interaction for trees, but no source code shipped—just a concept demo.
Article about Claude Opus 4.7 with no actual tool or code.
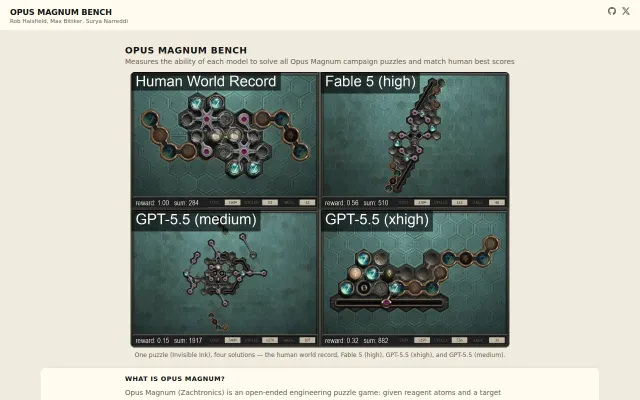
Game-based AI benchmark measuring spatial reasoning against human speedrun records.