Developer Tools●Mid
Rapunzel – a tree-style terminal for AI agents
Tree Style Tabs for agents, but 7 commits and 2 stars says embryonic.
Ship ItNiche Gem
WasimBhai
112mo ago
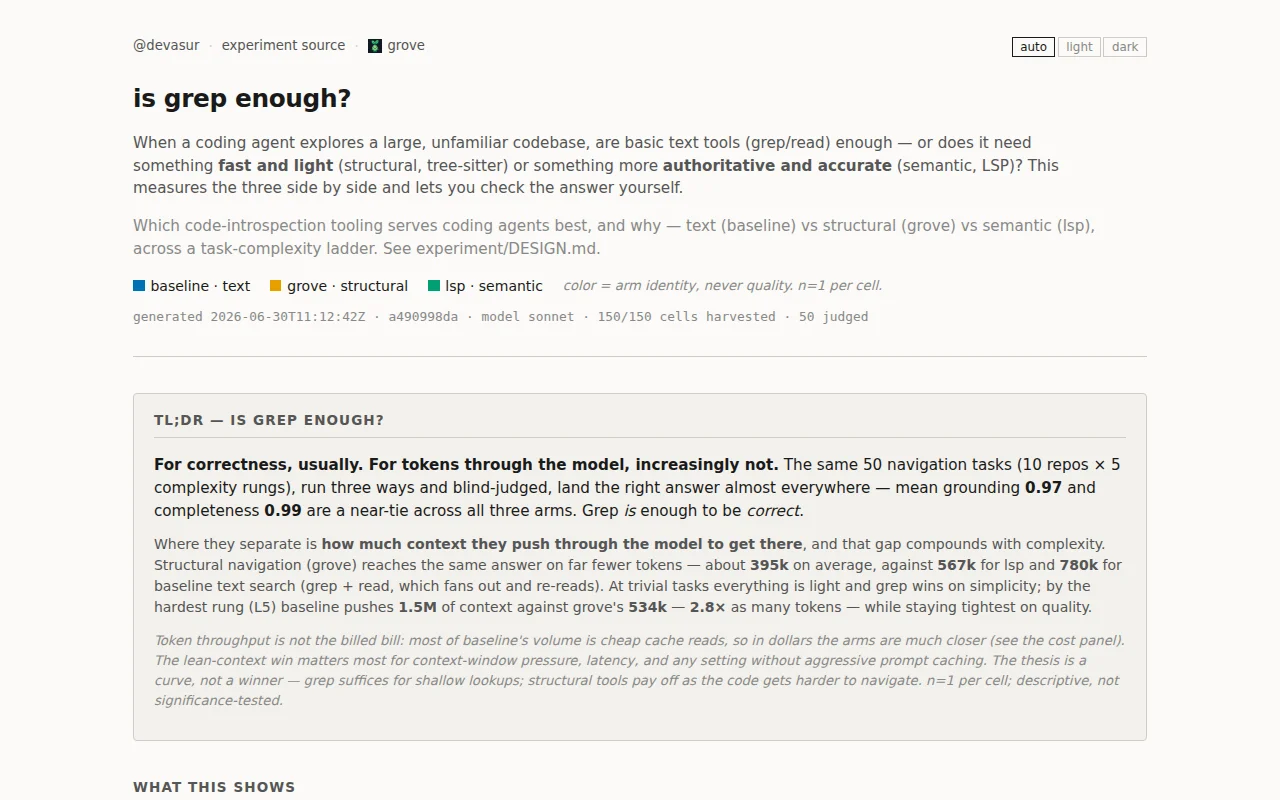
Grep wins on correctness, but tree-sitter cuts tokens by 50% on hard tasks.
AI agent developers, tooling engineers
Tree Style Tabs for agents, but 7 commits and 2 stars says embryonic.
llms.txt tree structure lets agents navigate context instead of dumping everything.
Tree-style tabs for agent sessions solve the flat-terminal scaling problem nicely.
44% cheaper Claude code navigation via tree-sitter definitions + call resolution.
Self-benchmark shows Sentinel uses 57x fewer tokens than browser-use on hard tasks.
Instruction tuning on tool descriptions cut Sonnet costs 29% without code changes.