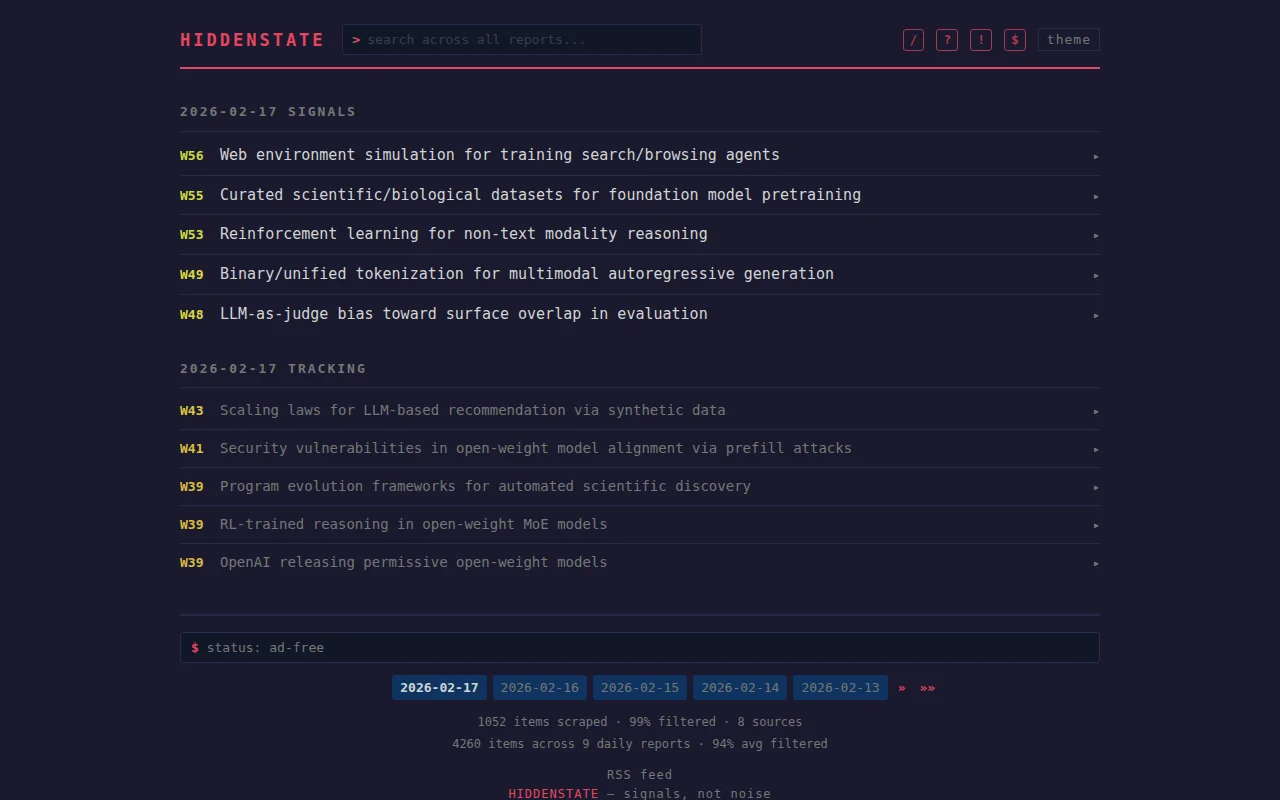
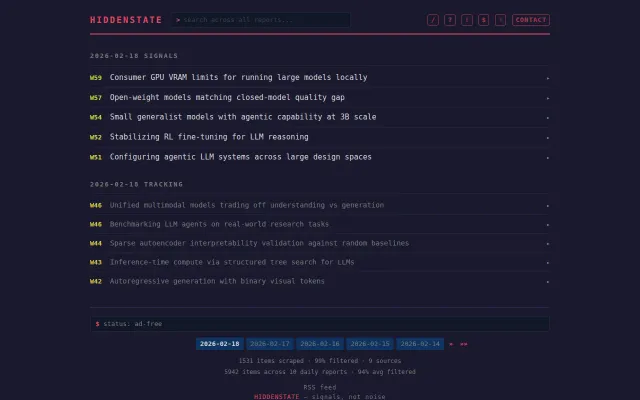
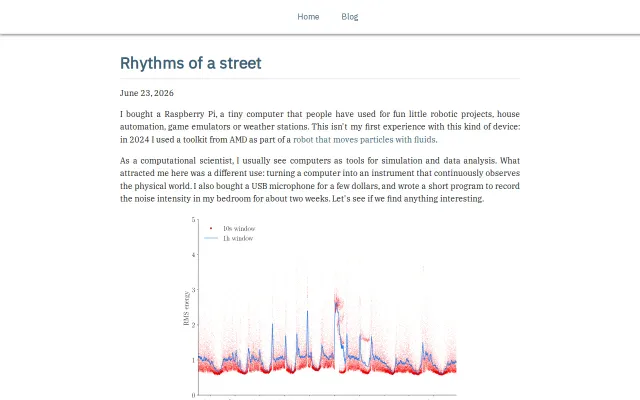
HiddenState monitors the ML ecosystem every few hours and clusters what it finds by the specific mechanism being worked on. Not by topic. By what constraint is being attacked and by whom alongside a detailed summary with sources.
Today it processed over 1,000 items. Three unrelated groups all released web environment simulators for training browsing agents within 24 hours. Curated biological datasets for ML pretraining appeared on PapersWithCode and Bluesky simultaneously from completely different orgs. Three separate papers applied RL to extend reasoning beyond text modalities. If you're working in any of those areas, that convergence matters and it's not something you'd catch from any single feed. Importantly, it gives you an insight into which direction the ML glacier is moving in.
Each mechanism is scored 0 to 100 on convergence across independent sources, implementation evidence, engagement, and significance. Orgs are deduplicated so the same lab appearing across platforms doesn't inflate the signal. Most ML aggregators summarize, meanwhile HiddenState acts as a filter. 99% of what it collects gets thrown out.
Python, SQLite, Claude for clustering, Cloudflare Pages. Free, no tracking.
Let me know if you were aware of any of today's/recent patterns or if you have feedback for improving the site or methodology. Cheers!