Developer Tools●●Solid
Yardstiq – Compare LLM outputs side-by-side in your terminal
One-command model comparison with real-time streaming and performance metrics beats tab-switching.
Solve My ProblemSlickCrowd Pleaser
stanleycyang
203mo ago
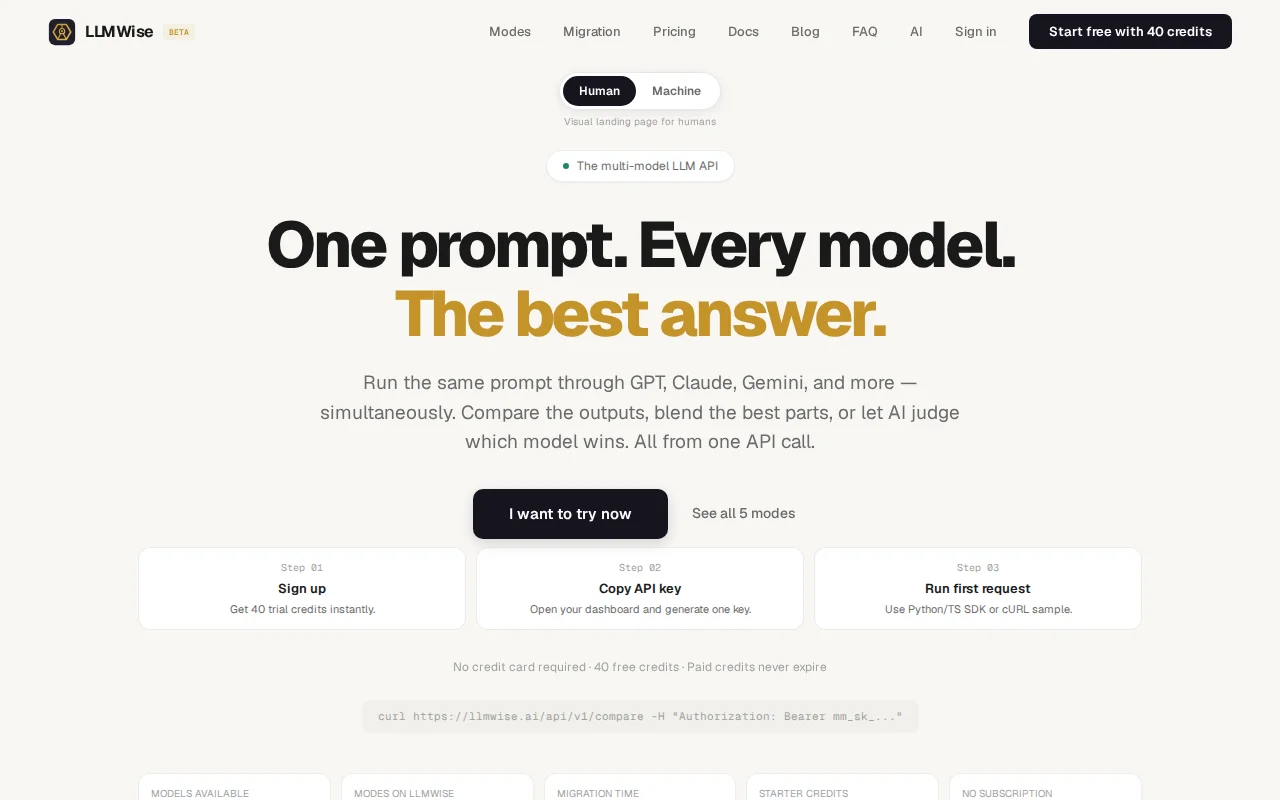
Multi-model orchestration with MoA blending and circuit-breaker failover, but LiteLLM and Anthropic Batch already exist.
Backend engineers, AI teams reducing LLM risk, API builders needing multi-model inference.
LiteLLM · Anthropic Batch API · Replicate
Mixture-of-Agents (MoA): Our /blend endpoint implements multi-layer MoA. You send a prompt to 2-6 models in parallel, then each model refines its answer using the other models' outputs as reference material. This runs for 1-3 configurable layers before a synthesizer model produces the final response. We also built a Self-MoA variant: a single model generates 2-8 diverse candidates using temperature variation and distinct agent prompts ("prioritize correctness", "anticipate edge cases", "be skeptical"), then synthesizes the best parts. Six blend strategies total: consensus, council, best_of, chain, moa, and self_moa.
Circuit breakers: Every model has a health tracker with a classic closed to open to half-open state machine. Three consecutive failures trips the circuit for 30 seconds. When a model is down, mesh routing automatically skips it and tries the fallback chain, so no wasted latency on providers that are having a bad day. The SSE stream emits route events so you can see exactly what happened: trying, failed, skipped(circuit_open), trying, success. OpenRouter gets its own tuned thresholds (6 consecutive 429s, 20s cooldown) because rate limits there behave differently than hard failures.
Auto-router: model: "auto" does zero-overhead heuristic routing, pure regex classification, no LLM call. Code goes to GPT, math/creative goes to Claude, translation goes to Gemini Flash, etc. Simple, fast, and surprisingly effective for common queries.
Other things that were fun to build:
- Credit settlement with margin targeting: we reserve credits upfront, then reconcile against actual provider cost after the response completes - Per-user semantic memory via pgvector: conversations build retrievable context across sessions - BYOK encryption (Fernet/AES-128) so you can bring your own API keys and skip our billing entirely
The whole backend is async Python (FastAPI + asyncpg + LiteLLM), frontend is static Next.js served by the same FastAPI process in production. Single Docker image on Railway.
For the technically curious: https://llmwise.ai/llms-full.txt has the complete platform documentation in plain text, and there's also a machine-readable view at https://llmwise.ai/ai designed for AI agents to consume.
One-command model comparison with real-time streaming and performance metrics beats tab-switching.
Prompt versioning is nice, but web tools and Cursor already do side-by-side comparison.
Yet another prompt benchmarking UI when Promptfoo and LangSmith already exist.
Schema conformance checks beat generic text evals for JSON-heavy LLM pipelines.
Handy prompt refiner, but prompt engineering itself is becoming obsolete with better base models.
Pytest syntax for LLM testing avoids LLM-judge cost, but feature parity vs. LangSmith and Braintrust unproven.